 Itamar Syn-Hershko
Itamar Syn-Hershko
OpenSearch and Apache Solr are both built on top of Lucene, and being used globally by leading companes as a text and vector search engine. Which one you should pick?

In today's data-driven world, search capabilities play a crucial role in big data applications. Whether it's e-commerce, enterprise search, log analysis, or AI-driven analytics, organizations require fast, scalable, and efficient search engines to retrieve and process information. The ability to search, analyze, and extract insights from large datasets efficiently can significantly impact business decisions and user experience.
Apache Solr and OpenSearch are two of the most widely adopted open-source search platforms, each offering unique advantages in different use cases. Both search engines leverage Apache Lucene, a library implemented in Java that has been present on the market for 25 years now and became one of the industry standards for building full-text search applications. While Apache Solr has been taken under the Apache Software Foundation umbrella relatively quickly after being implemented for CNET by Yonik Seeley, the OpenSearch is a more recent endeavour. OpenSearch started its life as a fork to Elasticsearch started by Amazon quickly after Elastic announced the licensing changes. You can learn more about the differences between Elasticsearch and OpenSearch on our blog post - OpenSearch vs Elasticsearch comparison.
When comparing these two search engines, it is essential to consider multiple aspects. Users thinking about each of the search engines look at them from different angles, considering multiple things including architecture, licensing models, feature sets, and overall ecosystem around the search engine. The right choice depends on specific requirements that the organization has.
This article provides a detailed comparison between Apache Solr and OpenSearch, covering core architecture, performance, query capabilities, security, and more. By the end of this discussion, you should have a clear understanding of which solution best fits your needs and how each platform aligns with your business or technical requirements. However, it is crucial to remember that there is no search engine that does it all and will be the best for all use-cases.
Before we start with the discussion about the search engines, let’s start with a comparison of Google Trends for both of them:
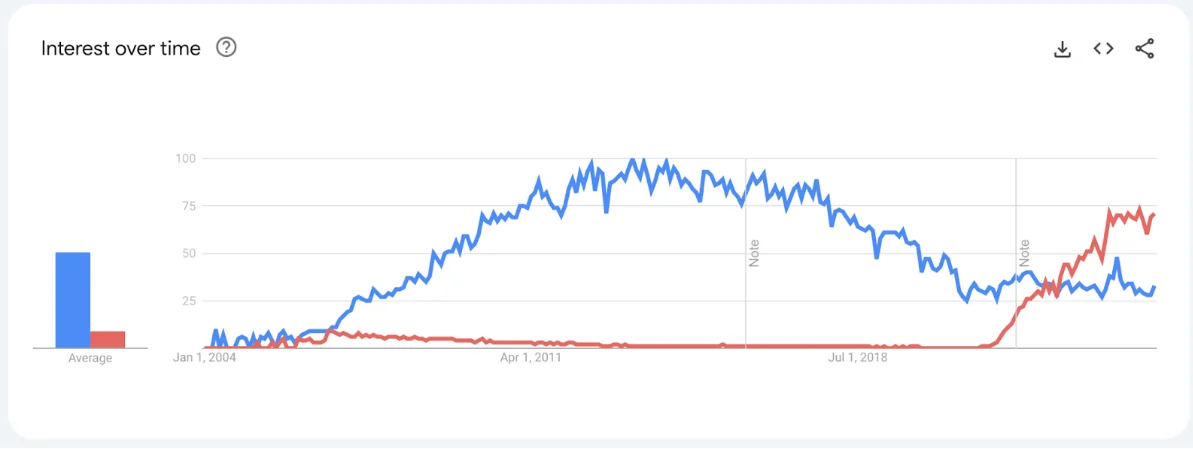
Google Trends for Apache Solr (blue) and OpenSearch (red)
Quick Overview
For those of us who are not keen on reading longer blog posts or are in a hurry, we start off with a quick comparison in the form of a table. However, we highly encourage you to spend some time and dig into each section, to learn more and have a better understanding of those two great search engines.
| Feature | Apache Solr | OpenSearch |
| Core Architecture | Built on Apache Lucene, supports leader-follower and SolrCloud modes using Apache Zookeeper for coordination. | Distributed architecture, built-in cluster management, no external Zookeeper required, uses Apaches Lucene for its full-text search capabilities. |
| Scalability | Requires explicit configuration, relies on Zookeeper for cluster management. | Automatic cluster management and scaling with built-in Zen discovery. |
| Indexing | Supports multiple formats (JSON, XML, CSV, rich documents). Uses collections and schemas. | Primarily JSON-based, it supports ingestion plugins for rich documents, structured as indices. |
| Query Language | Uses Apache Solr Query Parser and Lucene syntax, supports faceting, streaming expressions, and advanced queries. | Uses JSON-based Query DSL, includes aggregations, advanced ranking, and behavior-based search. |
| APIs | RESTful API with XML and JSON support, modern JSON API available. | RESTful API, compatible with Elasticsearch 7.x APIs. |
| Deployment | Runs on JVM, supports bare metal, VMs, containers, Kubernetes with Solr Operator. | Cloud-native focus, supports Kubernetes, Terraform, and traditional deployments. |
| Common Use Cases | Enterprise search, e-commerce, structured search. | Log analytics, observability, real-time search. |
| Vector Search | Uses Lucene-based dense vector fields, HNSW algorithm, supports external embeddings and reranking. | Uses Lucene-based dense vector fields, supports HNSW and Faiss, and various AI-driven search methods. |
| Performance | Optimized for batch indexing, uses global caching per index. | Optimized for real-time indexing, caches per segment for better performance. |
| Full-Text Search | Leverages Apache Lucene capabilities including stemming, multi-language support, tokenization, relevancy tuning, pluggable relevancy algorithm with various out of the box implementations based on term frequency and inverse document frequency. | |
| Faceting & Aggregations | Strong hierarchical faceting, powerful for e-commerce. | Aggregations engine provides control over data analysis with a highwith high degree of freedom. |
| Machine Learning | Limited ML features via streaming expressions, supports Learning to Rank. | ML Commons plugin includes anomaly detection, neural search, regression, RAG, and clustering. |
| SQL Support | Uses Apache Calcite for SQL queries, and supports a subset of ANSI SQL. | Supports ANSI SQL with additional search-related extensions. |
| Multi-Tenancy | Collections provide data isolation. | Indices used for multi-tenancy. |
| Observability | Requires external tools like Prometheus and Grafana. | Built-in OpenSearch Dashboards for visualization. |
| Security | Supports Basic, JWT, Kerberos authentication, audit logging, SSL encryption. | Supports JSON web tokens, Active Directory, LDAP, OpenID, SAML authentication. |
| Backups | Supports remote backups (S3, HDFS), manual snapshot management. | Snapshot management policies for automated backups with support for various storage backends. |
| Cross-Data Center Replication | Uses Apache Kafka for replication across clusters. | Active-passive model, follower index pulls data from leader without external software. |
| Ecosystem & Plugins | Supports manual extensions installation or using package management. | Large ecosystem of plugins for ML, security, ingestion, and visualization. |
| ETL Integration | Works with Apache NiFi, Logstash; ingestion pipelines support via update processors. | Integrates with Fluentd, Logstash, Vector, Data Prepper, OpenSearch Ingest Pipelines and others that can work with Elasticsearch/OpenSearch API. |
| Visualization | No built-in visualization; relies on external tools like Apache Zeppelin or Grafana. | Built-in OpenSearch Dashboards for real-time visualization. |
| Community & Support | Long-standing ASF project, slower development pace. | Actively developed by AWS and community with Linux Foundation support, frequent updates. |
| Enterprise Support | Supported by third-party vendors. | AWS-backed managed services, Red Hat development aid, Pulse support. |
| Popularity & Adoption | Popular for structured search, still widely used in publishing and e-commerce. | Gaining traction in log analytics, observability, vector search and real-time applications. |
Technical Comparison
We begin with the high level technical comparison.
Core Architecture
Let’s start by stating the obvious - both OpenSearch and Apache Solr are distributed search engines, however the initial architecture that Solr was designed with was the leader - follower architecture. With the version 4.0 it brought the fully distributed mode to the wide audience. On the other hand Elasticsearch and thus OpenSearch was built with a distributed environment in mind. Because of that some of the Solr features have limitations that come from the initial implementation details.
As we already mentioned Apache Solr is a distributed search engine built on top of Apache Lucene, providing full text indexing and search capabilities. We can say that it comes in two flavours - a traditional leader-follower architecture and so called SolrCloud, its distributed mode, that relies on Apache Zookeeper for cluster coordination. In its SolrCloud mode it allows for horizontal scaling, supports sharding and replication to ensure fault tolerance and high availability. Solr organizes its data in collections, which are divided into shards and replicas to distribute the data across the nodes.
OpenSearch, on the other hand, is a distributed search and analytics engine designed with modern cloud deployments in mind. It follows a decentralized architecture with built-in cluster management and automatic node discovery, simplifying the deployment process. Unlike Solr, OpenSearch does not require an external coordination service like Zookeeper; instead, it manages cluster states internally, making it easier to scale dynamically. It organizes its data in indices and similarly to Solr allows dividing them into shards and replicas for distributed processing.
Both platforms support multi-node clusters, but OpenSearch's design allows for more flexible and automated scaling, especially in cloud-native environments. Organizations looking for a search solution with minimal maintenance overhead may find OpenSearch's approach more convenient, while those requiring deep customization and control may prefer Solr.
Scalability
Both Solr and OpenSearch are designed to scale horizontally, but they differ in how they handle scalability and cluster management. SolrCloud manages its scalability through Zookeeper, which manages node coordination, leader election, and failover processes. Of course the majority of the logic is on Solr side, but the persistence of the cluster state and operations around it are done using Zookeeper. While this provides fine control over cluster operations, it also introduces additional complexity and maintenance burden - you are no longer only maintaining Solr, but also Zookeeper which has to operate efficiently and without disruptions.
OpenSearch, by contrast, has a built-in cluster state management mechanism, allowing nodes to automatically join and leave clusters without manual intervention - the so-called discovery implementation is called Zen. This simplifies cluster operations and makes OpenSearch more suited for cloud-native environments, where scaling up or down based on demand is a common requirement. Keep in mind that scaling is not free though and affects the cluster, especially when you have to move the data around, which not only requires processing power, but also network resources and time and in real production systems, especially those under high load, requires proper configuration and monitoring.
One thing that we should mention is that Apache Solr requires explicit configuration to scale efficiently, including managing leader shards and replica distribution. In contrast, OpenSearch automatically balances shards and nodes, reducing operational overhead. This makes OpenSearch more suitable for dynamic scaling scenarios, such as those found in Kubernetes-based deployments.
In both cases it is recommended to have dedicated nodes handling the discovery and state - in case of Apache Solr you would need to have a dedicated Zookeeper ensemble with at least 3 nodes for high availability and in case of OpenSearch you would keep the dedicated master nodes.
Indexing
One of the main roles of the search system is to properly index the data preparing for efficient query time retrieval. Both Apache Solr and OpenSearch leverage functionality of the Apache Lucene library exposing its functionality and expanding its features.
Apache Solr allows indexing data in various formats out of the box, starting from JSON, going through XML and finishing on CSV, not to mention binary types such as PDF or other rich documents using OCR built in into the search engine. The data is organized into collections, which share a common schema describing the data structure and how it should be processed. Apache Solr supports dynamic and statically defined schema, though you should keep in mind that the dynamic schema is intended for experimentation and shouldn’t be used in a production environment.
By default, OpenSearch allows indexing data in JSON format supporting indexing of single documents as well as batches for efficient indexing. The dedicated ingestion plugin allows expanding its functionality with rich documents content and metadata extraction, supporting popular formats such as PDFs, Microsoft Office documents, and other. Additionally, OpenSearch supports advanced ingest pipelines, allowing for transformations, enrichment, and processing of documents at the time of ingestion. Its data is organized into indices, which function similarly to collections in Solr. Each index has a defined mapping that dictates the structure of the data and how fields should be processed. OpenSearch provides both dynamically generated mappings and explicitly defined mappings, giving users flexibility in structuring their data. While dynamic mapping is available and can be useful for quick prototyping, it is recommended to use explicitly defined mappings in production environments to ensure consistency and optimal query performance.
Query Language
Data preparation is a very important step, but it is just a step that allows data retrieval. Both search engines offer extensive data retrieval capabilities, but it is important to get into the details to know more.
Solr has been with us for quite some time. Through the times we’ve seen changes to its APIs, its extensions and introduction of a new API - a more modern one. However, Solr primarily relies on the Solr Query Parser and its extensions and Lucene Query Syntax for search operations. These provide flexible full-text search capabilities, supporting complex Boolean queries, phrase searches, and range filters. It also includes faceted search capabilities allowing analysis on the returned search data crucial for providing insights into the data supporting filtering and data insights. Finally, Solr provides streaming expressions, not very well known, but a very powerful data analysis tool allowing complex mathematical and statistical analysis on top of the data indexed in Solr, definitely worth checking.
However, this is not everything. Over the years Solr received support for way more than just boolean search with filtering. Just to mention a few - Solr query APIs provide support for function queries, joins, spatial search and query enhancements, such as spell checking, type-ahead support, more like this queries and allow for very granular control over the returned results with document re-ranking, results grouping and clustering or even transforming the structure of the returned documents.
OpenSearch, on the other hand, uses Elasticsearch’s Query DSL (Domain-Specific Language), which is JSON-based and offers a structured way to define search queries. This DSL allows users to construct highly complex queries with ease, making it more intuitive for developers familiar with RESTful APIs and JSON structures. OpenSearch comes with a very powerful aggregations engine allowing analysis and data extraction based on the results of the queries.
Similar to Solr, OpenSearch provides a rich set of queries to support different use cases, such as spatial queries, various join types or ones that use scripts to rank the returned document. What’s nice is OpenSearch out of the box support for user behavior insights via a dedicated feature which can be very useful when processing user generated signals, for example in e-commerce to enhance user search experience.
It is also worth noting that both platforms provide support for vector-based search, but we will get to that topic a bit later in the article.
APIs
As we already mentioned, both Apache Solr and OpenSearch provide RESTful APIs for indexing and searching data, but they differ in their design philosophy and ease of use. Solr's API is highly structured and well-documented, with a focus on providing extensive query capabilities through structured parameters. It supports responses in various formats, for example JSON and XML, making it versatile for different types of integrations. Solr also supports a second type of API, a JSON-based one, that is more modern, and supports the majority of Solr features.
OpenSearch, by contrast, inherits Elasticsearch’s extensive API ecosystem, offering a more modern and developer-friendly experience. It follows a RESTful approach with JSON as the default response format, which is widely used in modern web applications. Because OpenSearch started as a fork to Elasticsearch, it provides compatibility with Elasticsearch 7.x APIs and partially with its newer versions, allowing users to migrate from Elasticsearch with minimal changes. This backward compatibility makes OpenSearch an attractive option for enterprises already invested in the Elasticsearch ecosystem.
Both Apache Solr and OpenSearch provide cluster management APIs, however the ones provided by OpenSearch are more user-friendly and were designed for working in distributed environments by default.
Approach Comparison
Deployment
Being able to index the data and search it wouldn’t be possible at scale without the search engine being deployed somewhere, so that it can serve its purpose - being able to accept the data, deliver search and analysis results and provide uninterrupted service to all the applications using it.
Solr can be deployed in two modes, as we already mentioned, in the old fashioned leader-follower architecture, and as a distributed cluster using SolrCloud requiring Apache Zookeeper. Both approaches can be working on any environment where Java Virtual Machine is available - whether this is a bare metal server, a virtual machine, a container or an orchestrated environment such as Kubernetes. There is also an external Solr Kubernetes operator simplifying the deployment and management in this environment.
OpenSearch was designed with cloud-native deployments in mind, but similar to Apache Solr it can work in every environment where Java Virtual Machine is available, which means bare metal, virtual machine, container and more options for deployment. OpenSearch simplifies Kubernetes deployment by providing a dedicated operator and for those of you who use Infrastructure as a Code, OpenSearch provides a dedicated Terraform provider.
Common Use Cases
It is pretty common for Solr and OpenSearch to be used by different target audiences depending on their core strengths and weaknesses. Solr is often the preferred choice for enterprise search applications, and e-commerce platforms. Companies that rely on complex filtering, sorting, and hierarchical faceting find Solr’s feature set particularly useful.
OpenSearch, on the other hand, is widely adopted for log analytics, observability, and real-time search applications. Its integration with OpenSearch Dashboards and compatibility with Elasticsearch-based tools make it an excellent choice for monitoring and security analytics. Organizations using OpenSearch often leverage its real-time indexing and search capabilities to process large-scale logs and event data.
Vector Search
Vector search is becoming increasingly important in modern search applications, particularly for AI-driven recommendations, natural language processing, and semantic search use cases. Both Solr and OpenSearch are expanding their support for vector-based search, but they approach it slightly differently.
Apache Solr relies on Lucene's ability to index and search for embeddings to provide semantic or hybrid search. Solr is able to index vectors in the dedicated dense vector fields with configurable dimensions, vector similarity functions and potentially different k-nearest neighbours search algorithms. However, for now only a single implementation of the Hierarchical Navigable Small World algorithm is available. When it comes to the query time we have the option to use the k-nearest neighbors query parser when we want to provide the vector representation of the query or the k-nearest neighbors text to vector query in cases when we would like Solr to use a dedicated large language model to calculate the query embeddings automatically during query time. We also have the third option to use the vector similarity query parser allowing us to specify the minimum similarity for the data to be returned. In all cases we also have the option to pre-filter the documents we run the vector similarity or even use the vector search as a reranking query for the re-ranking query parser.
Similar to Apache Solr, OpenSearch implementation is based on the Apache Lucene to store the embeddings in the inverted index, so that the search engine is able to utilize them during query time. Another similarity is that we can rely on external models to provide the embeddings and include them in the data we send to the search engine, but we can also use OpenSearch to generate embeddings for us and here is where OpenSearch excels as it provides out of the box pre-trained models that we can use including models for sentence transformation, sparse vector encoding models, and ones for query re-ranking. When it comes to the search time OpenSearch provides various approaches. You can use query embeddings generated outside of the search engine and use the approximate k-nearest neighbors search with two implementations of Hierarchical Navigable Small World (HNSW) or Facebook AI Similarity Search (Faiss) algorithm. Or go for the model working inside OpenSearch and use semantic search, hybrid search, multimodal search, neural sparse search or even so called conventional search where your user searches are expressed in natural language.
Performance
When it comes to performance we should start with one of the big differences between Apache Solr and OpenSearch. To illustrate the mentioned difference let’s start with how Apache Lucene, the underlying library handles indexed data.
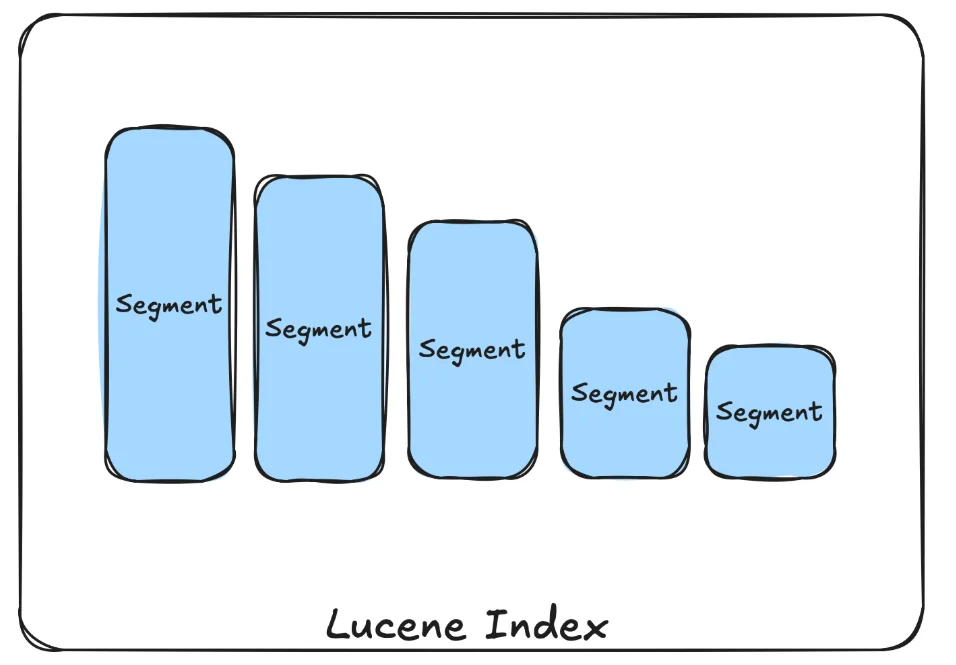
Lucene index is basically a shard, so a part of the collection in Apache Solr and index in OpenSearch. The segments of a Lucene index are produced when we index data, they are mostly immutable data structures that are built from multiple files and are very search optimized. One of the main differences between the discussed search engines is that Solr uses caches that are created for each Lucene index, while OpenSearch creates caches for each segment. Why is that important? In near-real-time indexing and searching scenarios the segments are often created and merged together because of performance reasons. When a single segment in the Lucene index changes Solr needs to invalidate and rebuild the cache for the whole shard, while OpenSearch handles the refresh only for the modified segments.
Performance comparisons between Solr and OpenSearch largely depend on workload characteristics, indexing strategies, and query patterns.
Apache Solr is known for its superior performance in batch indexing scenarios, where large amounts of data need to be indexed efficiently. Its global caching mechanisms allow for faster lookup times for queries on a fairly static dataset, making it a strong contender for structured search use cases.
OpenSearch, on the other hand, excels in real-time search applications. Its distributed nature and optimized indexing pipelines make it a preferred choice for log analytics, observability, and other scenarios that require near real time search results.
When we talk about performance we should also mention that both search engines provide the possibility to monitor their performance over time. In Solr's case this is done via exposed real time metrics which can be exported via Prometheus Exporter and visualized using Prometheus and Grafana. OpenSearch can also be monitored via Prometheus, but it also provides a dedicated Performance Analyzer which enables highly detailed visibility into cluster metrics to troubleshoot and analyze the cluster.
Features - Quick Comparison
Let’s now quickly discuss some of the other features that both search engines provide.
Full-Text Search
Both Solr and OpenSearch provide advanced full-text search capabilities, including stemming, tokenization, and relevancy tuning. OpenSearch enhances search pipelines with additional features like percolator queries, allowing users to match documents against predefined queries efficiently and has a more structured and user friendly API.
Faceting & Aggregations
Solr is widely recognized for its superior faceting capabilities, making it a go to choice for e-commerce applications that require hierarchical filtering. OpenSearch offers similar functionality via its aggregation functionalities which provides a more developer-friendly API for defining complex aggregations with OpenSearch providing more options and higher degree of control over the queries.
Machine Learning Capabilities
Both Apache Solr and OpenSearch provide machine learning functionalities beyond vector search. For example, they both support Learning to Rank - in Solr as an additional module and via OpenSearch plugin, but the features are not limited to this.
Apache Solr supports some machine learning capabilities in its streaming expressions - you can expect presence of K-Means clustering methods, feature scaling, and K-Nearest Neighbours search.
OpenSearch includes machine learning functionalities via ML commons plugin and includes features such as anomaly detection, RAG (Retrieval-Augmented Generation), neural search multimodal search and algorithms such as K-means, linear regression, RCF (Random Cut Forest), localization, logistic regression, and metrics correlation.
Just by looking at the above we can see that OpenSearch provides a richer set of machine learning based features compared to Solr.
SQL Support
Both platforms offer SQL-like query interfaces. Apache Solr uses the Apache Calcite SQL engine to translate the SQL queries to streaming expression plans allowing it to support the subset of ANSI SQL with some limitations. On the other side we have OpenSearch which also supports a subset of the ANSI SQL, but also provides extension functions including relevance search and aggregate functions.
The mentioned search engines can be integrated with business intelligence tools via the provided JDBC driver and in case of OpenSearch also the read-only ODBC driver for Microsoft Windows and MacOS.
Multi-Tenancy
Both Apache Solr and OpenSearch support multi-tenancy features allowing data isolation inside a single cluster with Solr providing collections and OpenSearch providing indices for that purpose.
Observability
OpenSearch has built-in observability tools, including OpenSearch Dashboards for visualizing search metrics. Apache Solr requires third-party solutions like Prometheus with the exporter module and Grafana for visualization to achieve similar observability functionalities.
Security
Apache Solr provides a security framework supporting authentication, authorization and user auditing allowing user identity verification and resource restriction. It can be configured to use various forms of authentication such as rule based, Basic, JWT, Kerberos or even certificate based. It also allows for audit logging for user actions visibility, can be configured to communicate over SSL, supports Zookeeper access control lists and includes basic UI for managing security, such as user roles and permissions.
OpenSearch doesn’t fall short when it comes to its security offering. By design it was built with security in mind supporting encrypted communication, authentication via simple credentials, JSON web token or TLS certificate. Users, their credentials, roles and permissions can be stored in the built-in database or can be externally fetched with the help of protocols such as Active Directory, LDAP, SAML and OpenID. Similar to Solr, OpenSearch includes audit logging tracking the users behavior for compliance purposes. And finally, OpenSearch Dashboards, even though they are not the search engine itself, but it is worth noting that they support security and multi-tenancy as well.
Backups
Both Apache Solr and OpenSearch provide the ability to backup the data to a remote location, such as an S3 bucket and put a snapshot of the data and metadata for future use. However OpenSearch provides a more extensive and user-friendly API with the possibility to use so-called snapshot management policies to allow automation of the snapshotting process using the Index Management Plugin.
Cross-Data Center Replication
When looking at the newest version of both search engines, I can say that both Apache Solr and OpenSearch provide cross-data center replication of the data. They both follow a similar pattern, but of course differ in details and configuration. In both cases you define a leader cluster and a set of follower clusters and the data is copied from the leader cluster to the follower clusters allowing for eventual consistency without blocking the leader cluster and affecting its performance.
Apache Solr cross-data center replication relies on Apache Kafka cluster availability and uses it as a distributed queue where the leader cluster puts the data and requests and from which the so-called CrossDC manager pulls the data and sends it to the follower clusters.
When it comes to OpenSearch the architecture follows an active-passive model where the follower index pulls the data from the leader and doesn’t require any external software to work.
Ecosystem
Plugins, Extensions and More
The plugin ecosystems of Solr and OpenSearch offer various ways to extend their functionality, but if you are familiar with the richness of the ecosystem surrounding Elasticsearch you probably expect something similar from OpenSearch and its ecosystem. Let’s discuss that now.
OpenSearch provides a wide range of official and community-developed plugins that enhance text analysis, discovery, machine learning capabilities, ingest pipelines, observability and much more. When we talk about plugins we should also mention a visualization layer for OpenSearch called Dashboards. Originating from Kibana, OpenSearch dashboards allow rich visualizations of the data indexed in OpenSearch.
Apache Solr allows installing plugins in multiple ways - either by manually putting the needed libraries in appropriate directories, using the package management features and a blog store that is considered deprecated and is a predecessor to the package management functionality. It follows a more configuration-driven approach, where after installation you should also configure the plugin to be able to use it.
ETL
Efficient ETL workflows are essential for processing and indexing large datasets into search engines. Both Solr and OpenSearch offer ETL capabilities, but OpenSearch has better integration with modern data pipelines.
Solr supports ETL workflows through tools like Apache NiFi, Logstash, and custom-built ingestion pipelines called update processors. However, these integrations often require additional configuration and development efforts. Solr used to provide out of the box integration for structured data ingestion from relational databases via the DataImportHandler, but it is now an externally maintained plugin that is no longer commonly used.
OpenSearch, on the other hand, integrates seamlessly with tools like OpenSearch Data Prepper, Vector, Logstash, Fluentd, and provides Ingest Pipelines for streamlined data ingestion. In fact it integrates with a large library of tools, ones that support Elasticsearch/OpenSearch API. The mentioned pipelines are very configurable and powerful enabling OpenSearch to pre-process and transform the data before it is indexed, reducing the need for external ETL tools in many cases.
Visualizations
Depending on your needs the visualization right on top of OpenSearch or Apache Solr may or may not be your primary use-case, but it is certainly useful for understanding the data without any external tooling. Just by looking at the tools with tight integrations OpenSearch has a clear advantage in this area due to its built-in visualization tool, OpenSearch Dashboards.
OpenSearch Dashboards is a powerful, flexible UI that allows users to build visualizations, dashboards, and reports for search and analytics data. It is particularly useful for log analytics, observability, and monitoring use cases. OpenSearch Dashboards support real-time data updates, making it highly effective for dynamic search environments.
Apache Solr, in contrast, does not include a native visualization tool. Instead, it relies on third-party solutions such as Apache Zeppelin, Banana or external BI tools like Tableau. While these tools offer strong visualization capabilities, they require additional configuration and are not as seamlessly integrated with Solr as OpenSearch Dashboards is with OpenSearch.
Community & Support
Community and the support behind the search engine play a crucial role in long-term adoption. Large, active and supportive community brings new users, gives feedback and extends the platform functionality where they see need. Vendors, in a healthy environment make sure that the platform is going into the direction that the market needs and support the growth of the whole product. Apache Solr and OpenSearch differ significantly in their community engagement, development contributions, and enterprise support models.
Community Engagement
Apache Solr has a long-established open-source community managed under the Apache Software Foundation (ASF). It benefits from a fairly stable and dedicated group of contributors who focus on maintaining and improving the platform. Back in the days Apache Lucene and Apache Solr had the same group of committers, but nowadays those are two, separate top level Apache Software Foundation projects with separate committers. The Apache model ensures that Solr development is community-driven, with decisions made collectively and transparently. However, its rate of innovation can sometimes be slower compared to commercial-backed projects, as it relies primarily on volunteer contributions and corporate sponsorships.
OpenSearch, in contrast, was developed as a response to Elastic’s licensing change, with AWS taking the lead in its development initially. Basically it started as a fork to Elasticsearch and parts of its ecosystem. It is supported by a rapidly growing community, including developers from AWS, Red Hat, and other enterprises, but it is now a part of the Linux Foundation and is maintained and developer under its umbrella. OpenSearch’s development is highly active, with frequent updates and improvements driven by both the open-source community and AWS’s engineering teams. The OpenSearch community actively engages through forums, GitHub discussions, and regular roadmap updates.
If we would like to get some insights, we can look at the contributions to the main projects (from GitHub Pulse) and the count of contributors (from Black Duck Open Hub):
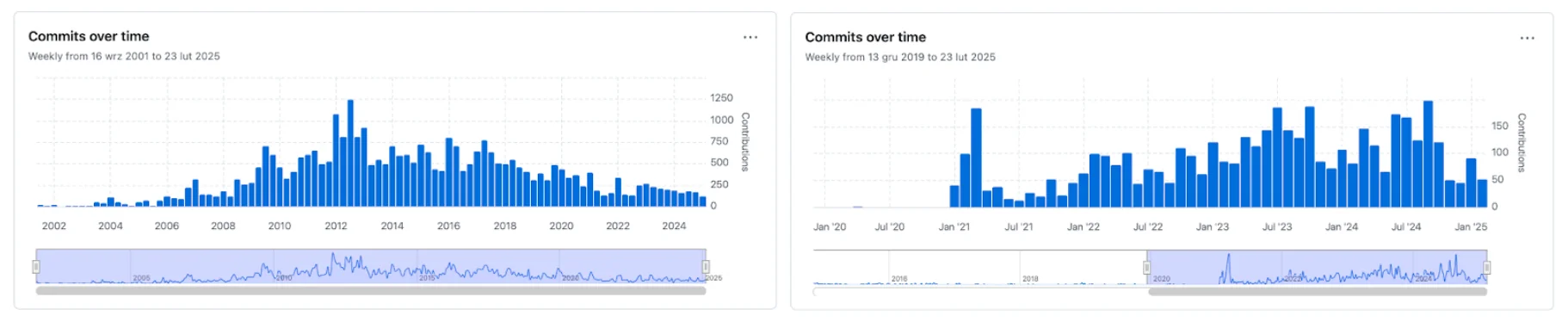
You can see that the peak contributions to Solr - on the left was around 2012 - 2013 with a lot less contributions lately, with OpenSearch having a varying degree of contributions.
And when it comes to contributors the data looks as follows:
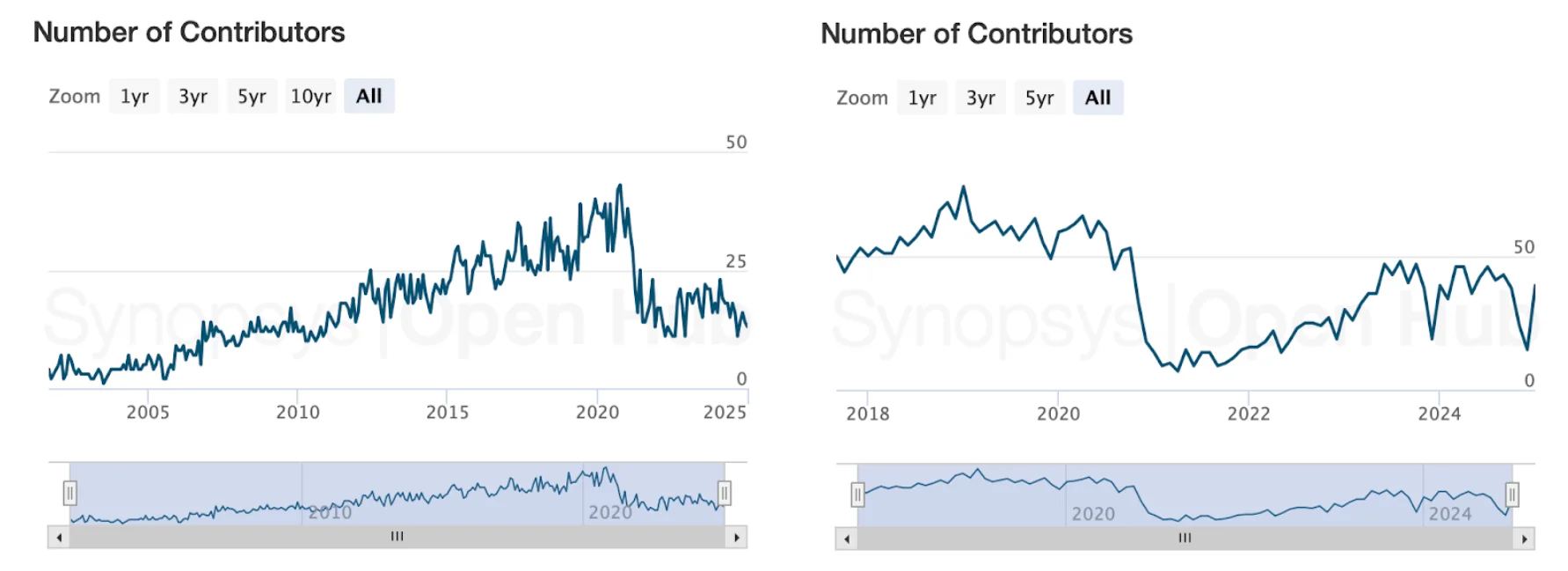
You can see that the number of contributors hit an all time high around 2020 for Solr and around 2019 for OpenSearch and now fell down below 25 for Solr and 50 for OpenSearch.
Enterprise Support and Vendors
Apache Solr is primarily supported through third-party vendors and consulting firms, providing commercial Solr-based solutions. However, official enterprise support is not as structured as OpenSearch’s, and organizations typically rely on internal expertise or third-party service providers for troubleshooting and performance optimization.
OpenSearch, on the other hand, benefits from direct support from AWS, which offers fully managed OpenSearch Service on AWS Cloud. This makes it an attractive option for businesses looking for a cloud-hosted search engine with dedicated support and SLAs. Other vendors, such as Aiven and Red Hat, also provide managed OpenSearch services, further strengthening its enterprise viability.
Popularity and Adoption
Solr has been a staple in enterprise search for over a decade and is widely used in large organizations requiring structured search and faceted navigation. Industries such as publishing, legal research, and e-commerce continue to rely on Solr for their search needs.
OpenSearch is rapidly gaining traction, particularly in the log analytics and observability space, where real-time search and scalability are critical. Many former Elasticsearch users have migrated to OpenSearch due to its open-source licensing model and continued feature development.
Conclusion
Both Apache Solr and OpenSearch are powerful open-source search engines with distinct advantages. While Solr is still a solid player in the world of search because of its maturity and excellent performance for applications with fairly static data, requirements are not the same as they used to be a few years ago.
Organizations are not only seeking support for rapidly changing data, ease of maintenance and developer friendliness now, but also judge the platform by its ecosystem and long term support potential - from experts and commercial entities being able to help through the software development life cycle. OpenSearch shines in this regard, being easier to run and maintain, being less dependent on external infrastructure elements, having more modern APIs and a rich ecosystem surrounding it. It was built with cloud-native deployments in mind, with automatic scalability. And we can’t forget about the platform use cases such as log and metrics analytics which OpenSearch supports out of the box.
Following a continous decline in Solr adoption in recent years, we see increasing adoption of OpenSearch especially with cloud native and greenfield projects. Enterprises and corporations are more likely to be using Solr today, mostly for historical reasons; while smaller companies or new projects will lean to using OpenSearch or other alternatives.

