

OpenSearch Consulting & Implementation Services
Expert OpenSearch consulting from an OpenSearch Foundation member. BigData Boutique helps engineering teams deploy, optimize, and scale OpenSearch clusters — from Amazon OpenSearch Service migrations to advanced vector search and AI-powered relevance.
Talk to an Expert
Foundation
OpenSearch Software Foundation Member
Active contributor and governing member of the OpenSearch project.
Accredited
OpenSearch LTS Support Provider
First and accredited provider of long-term support for OpenSearch deployments.
AWS
Service Delivery for Amazon OpenSearch
AWS-validated expertise in delivering Amazon OpenSearch Service projects.
Led by an OpenSearch Ambassador
BigData Boutique is an OpenSearch Foundation member, and an accredited OpenSearch LTS support provider. Our team is led by Itamar Syn-Hershko, an OpenSearch Ambassador and active contributor to the OpenSearch project since its earliest days.

Our OpenSearch Consulting & Support Services
We have been helping clients leverage OpenSearch since the early days of the project. Our consulting and implementation approach covers deployment, migration, performance tuning, and production support — tailored to your specific use case and scale.

Migration assistance to/from Amazon OpenSearch Service, other managed services, or self-managed clusters — with zero downtime

Elasticsearch to OpenSearch migration and OpenSearch version upgrades with full compatibility validation

OpenSearch Production Support and 24/7 Emergency Response Team.

OpenSearch consulting and implementation for log analytics, observability, enterprise search, and vector search

Enterprise Search and Relevance Engineering with learning-to-rank and AI-powered vector search
Client Results
BigData Boutique helped Yotpo reduce operational overhead for their mission-critical offering by migrating a self-managed cluster on EC2 to Amazon OpenSearch Service.
Read the story

MAX Security
BigData Boutique collaborated with MAX Security to develop SCOUT AI, an Agentic RAG application enabling accelerated decisions based on real-time intelligence leveraging Amazon OpenSearch Service, hybrid search, and more.
Read the story
BigData Boutique supported building Boomi's Portable Knowledge Base — the core of Boomi's RAG pipeline at global scale. The solution ingests documents, performs validation, chunking, and embedding via AWS Bedrock, then indexes results into OpenSearch.
Completed migration of Alamy's workloads from Apache Solr to Amazon OpenSearch Service — supporting hundred-million scale hybrid media search with high scalability and performance requirements.
What Our Clients Say
BigData Boutique helped Yotpo migrate a 50 TB Elasticsearch cluster from EKS to Amazon OpenSearch Service in just 8 hours — with zero downtime!
Dan Gleyzer
Senior Backend Developer at

BigData Boutique's deep expertise in search and AI was essential to building SCOUT AI. They combined OpenSearch, AWS Bedrock, and advanced embeddings to turn our vast intelligence archive into a tool analysts can query in seconds.
Dror Becker
CEO at

We needed more than a search vendor — we needed a partner who could understand how our users think. BigData Boutique's mix of AI innovation and infrastructure know-how delivered exactly that.
Greg DeVore
CEO at

The understanding of search technologies and insight BigData Boutique were able to provide was absolutely UNBELIEVABLE.
Pavel Klushkin
Solutions Architect Team Lead at

BigData Boutique were very knowledgeable and particularly helpful with the more complex topics of search technologies, relevance and ML.
Avi Arfin
Search Engineering Manager at

You can tell just by talking to BigData Boutique, how deep their knowledge in search technologies is.
Gio Bagtas
Director of Engineering at

How We Work
1
Cluster Assessment
We audit your OpenSearch environment — mappings, queries, shard strategy, and infrastructure — to identify bottlenecks and risks.
2
Architecture Design
We design an optimized OpenSearch architecture tailored to your use case — sizing, tiering, index strategy, and security configuration.
3
Implementation
Our engineers execute hands-on implementation — migrations, upgrades, and integrations — with zero downtime and full rollback plans.
4
Ongoing Support
24/7 monitoring, proactive alerting, and continuous optimization to keep your OpenSearch cluster healthy and cost-efficient.
Expert OpenSearch Consulting & Support
Running OpenSearch in production requires more than just spinning up a cluster. From index design and shard strategy to query optimization and capacity planning, the decisions you make early on determine your cluster's long-term performance and cost profile. Our OpenSearch consulting engagements give your team direct access to engineers who have deployed and optimized thousands of clusters across log analytics, enterprise search, observability, and AI-powered use cases.
Whether you need help migrating to Amazon OpenSearch Service, troubleshooting production issues under pressure, or building a vector search pipeline from scratch, our OpenSearch support team is here to help. We offer both project-based consulting and ongoing support plans with guaranteed SLAs — so you get the right level of assistance for your stage and scale.
OpenSearch Production Support & LTS
Beyond project-based consulting, we provide ongoing OpenSearch production support with guaranteed SLAs — 24/7 incident response, proactive monitoring, and hands-on troubleshooting for mission-critical clusters. Our support engineers are available via Slack, Teams, and email, not ticket queues or community forums.
We support both self-managed OpenSearch — on Kubernetes, EC2, or on-premises and airgapped environments — and Amazon OpenSearch Service deployments. As an accredited OpenSearch LTS (long-term support) provider, we maintain and patch older OpenSearch versions in production long after upstream support ends, so you can upgrade on your own timeline.
OpenSearch Capabilities We Cover
Our OpenSearch consulting engagements span the full feature surface of the OpenSearch project, from core cluster operations through AI-powered search. Below is a snapshot of the named capabilities our engineers work with day-to-day on customer clusters running OpenSearch 2.x and 3.x.
Vector Search & AI Integration
k-NN engine with Lucene HNSW, Faiss, and nmslib backends. ML Commons for embedding generation, Neural Search for vector-first queries, and hybrid search combining BM25 with dense retrieval. Conversational search, retrieval-augmented generation (RAG) pipelines, and integrations with Amazon Bedrock, OpenAI, Cohere, and Hugging Face for embedding and reranking models.
Cost & Storage Optimization
Index State Management (ISM) policies, hot/warm/UltraWarm/cold data tiers, searchable snapshots, segment merging strategy, shard right-sizing, and index template design. Cluster sizing aligned to workload, with measurable infrastructure spend reductions across indexing-heavy and search-heavy fleets.
Observability & Operational Tooling
OpenSearch Dashboards, the Observability suite (logs, traces, metrics), Anomaly Detection, Alerting, Security Analytics, and PPL (Piped Processing Language) for analyst workflows. Ingestion via Data Prepper, Logstash, Fluent Bit, and OpenTelemetry Collector.
Migration & Upgrades
Elasticsearch 6.x/7.x to OpenSearch migrations, OpenSearch 1.x → 2.x → 3.x version upgrades, Solr to OpenSearch migrations, and cross-cluster moves using snapshot/restore (S3, Azure Blob, GCS), the reindex API, and Logstash. Rolling upgrades with zero downtime and tested rollback plans.
Security & Compliance
OpenSearch Security plugin configuration: fine-grained access control at the index, document, and field level. SAML and OIDC integration, audit logging, TLS for transport and HTTP layers, and cross-cluster encryption. Compliance-ready setups for SOC 2, HIPAA, PCI-DSS, and GDPR environments.
Search Relevance Engineering
Query DSL design, analyzers and tokenizers, custom scoring, learning-to-rank, and the Search Relevance Workbench for measurable relevance tuning. A/B testing infrastructure and offline evaluation harnesses to keep relevance improvements honest.
High Availability & Scale
Cross-cluster replication for disaster recovery and read scaling, multi-AZ and multi-region topologies, dedicated master and coordinating nodes, snapshot lifecycle management, and capacity planning for indexing- and search-heavy workloads.
Deployment Platforms
Amazon OpenSearch Service (provisioned and Serverless), Aiven, Instaclustr, DigitalOcean, self-managed on Kubernetes (with the OpenSearch Operator), EC2, GKE, AKS, and on-premises. Multi-cloud architectures with consistent operational tooling across providers.
Built by Operators, Not Just Consultants
We do not just advise on OpenSearch — we operate it. Our team built Pulse, an observability and operations platform that powers production OpenSearch and Elasticsearch clusters across our customer base. Pulse gives us — and our customers — query analytics, cluster health intelligence, and proactive recommendations grounded in real-world cluster telemetry.
This operator mindset is what separates our OpenSearch consulting from generalist firms. The patterns, gotchas, and optimizations we share with clients come from running, scaling, and recovering OpenSearch clusters every day, not from documentation alone.
Learn more about Pulse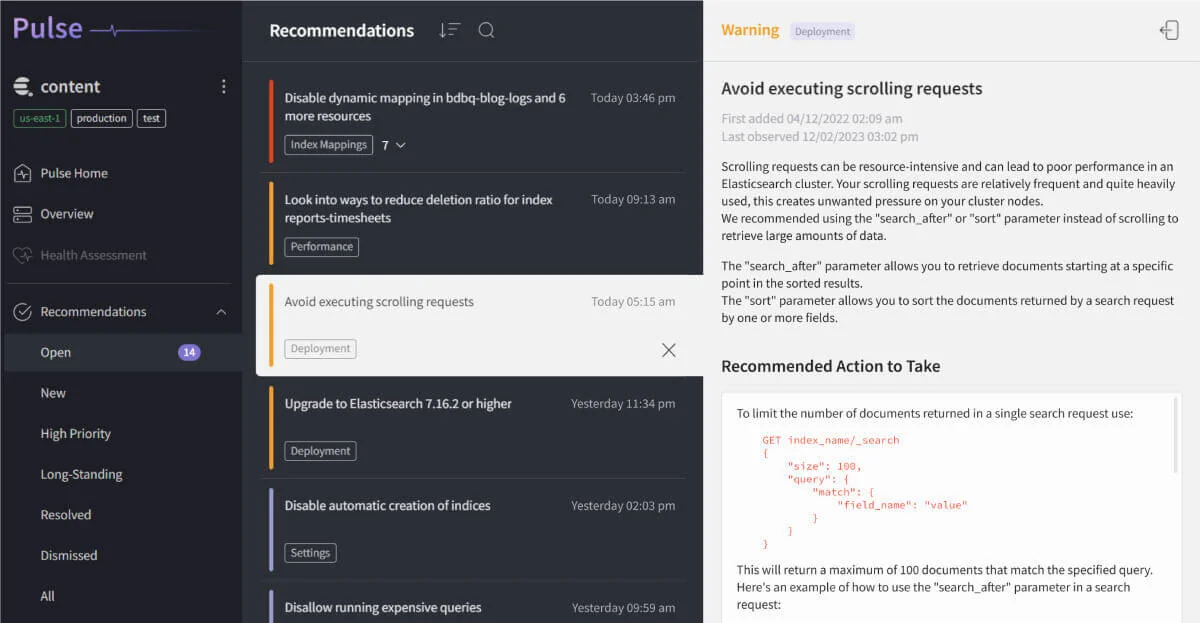
Why Choose BigData Boutique for OpenSearch Consulting?
| Capability | In-House | BigData Boutique |
|---|---|---|
| Developer Support | ChatGPT / Claude Code | Hallucination-free expertise |
| 24/7 emergency support | Requires dedicated team | Included |
| OpenSearch version upgrades | Risk of downtime | White-glove service available |
| Cost optimization | Trial and error | 30% avg reduction |
| Search relevance tuning | Requires ML expertise | 15+ years experience |
| OpenSearch project access | Community forums only | Code contributors & Foundation member |
From Our OpenSearch Blog



Frequently Asked Questions
What OpenSearch consulting services does BigData Boutique offer?
We provide end-to-end OpenSearch consulting including cluster deployment, migration to and from Amazon OpenSearch Service, performance tuning, cost optimization, search relevance engineering, and 24/7 production support. Our services cover the full OpenSearch lifecycle.
Can BigData Boutique handle Elasticsearch to OpenSearch migration?
Yes — this is one of our core specializations. We've performed hundreds of Elasticsearch to OpenSearch migrations with zero data loss and minimal downtime. Our process includes compatibility auditing, plugin migration, and phased cutover planning.
What does your OpenSearch production support SLA look like?
We offer tiered support plans with guaranteed response times starting at a 1-hour SLA for critical production issues. Our dedicated OpenSearch engineers are available 24/7 via Slack, Teams, and email — not community forums or ticket queues.
How does BigData Boutique reduce OpenSearch infrastructure costs?
We audit your cluster configuration, index lifecycle policies, shard strategy, and query patterns. By right-sizing nodes, implementing efficient ILM policies, and removing indexing inefficiencies, we consistently deliver 25–40% cost reductions for our clients.
What is BigData Boutique's involvement with the OpenSearch project?
BigData Boutique is an OpenSearch Foundation member and our team is led by Itamar Syn-Hershko, an official OpenSearch Ambassador. We contribute to the OpenSearch codebase, maintain open-source plugins, and actively participate in shaping the project roadmap — giving our clients access to insights that no external consulting firm can offer.
Should we run OpenSearch on Amazon OpenSearch Service or self-manage on Kubernetes?
It depends on your scale, version-currency needs, plugin requirements, and operational maturity. Amazon OpenSearch Service is the right choice for AWS-native teams that want minimal operational burden, but version lag and feature restrictions are real trade-offs. Self-managed OpenSearch — typically on Kubernetes via the OpenSearch Operator — gives you full control, day-one access to new versions, and lower per-node cost at scale. Our consulting engagements often start with this decision; we model the cost, operational, and feature trade-offs against your specific workload before recommending a path.
How do you approach OpenSearch version upgrades from 1.x to 2.x to 3.x?
Our upgrade process starts with a compatibility audit of mappings, plugins, query DSL usage, and client libraries. We test the upgrade in a staging environment, validate against production-like data and query traffic, and execute the production upgrade as a rolling upgrade with full rollback plans. For major version jumps, we typically use snapshot/restore to a parallel cluster, run dual-write or shadow-query patterns for validation, then cut over with zero downtime. Many of our clients also use this as a chance to consolidate indices, refresh shard strategy, and harvest the performance gains in newer OpenSearch versions.
Can BigData Boutique help build vector search, RAG, and AI-powered applications on OpenSearch?
Yes — this is one of our most active practice areas. We design and deploy production vector search using the OpenSearch k-NN engine (Lucene HNSW, Faiss, and nmslib backends), ML Commons for embedding pipelines, Neural Search for vector-first queries, and hybrid search combining BM25 with dense retrieval. For retrieval-augmented generation, we build end-to-end pipelines that handle chunking, embedding (via Amazon Bedrock, OpenAI, Cohere, or open-source models), retrieval, reranking, and prompt construction. Recent customer engagements include hundred-million-document hybrid media search and agentic RAG over real-time intelligence archives.
Ready to Get Started?
Get in touch with our OpenSearch experts or schedule a meeting to discuss your needs.