 Dinor Nagar
Dinor Nagar
Discover how Cohere Embed 4 enables a 3x reduction in embedding size with no loss in search quality. Learn how to cut memory use and costs in Elasticsearch or OpenSearch with real-world hybrid search results.

Shrinking your vector embeddings can save memory and money - but will it hurt your search quality? In this post, we test Cohere’s new Embed 4 model, which promises state-of-the-art efficiency even at lower dimensions. Here’s how we cut our embedding size by 3x in a real-world search system, with no loss in retrieval performance.
On April 15 2025, Cohere introduced a new embedding model named Embed 4, which was claimed to “deliver state-of-the-art accuracy and efficiency”. The new embedding model was trained using the Matryoshka Representation Learning, a method that claims to create an embedding model whose embeddings could reasonably shrink without a significant loss in performance. This is a crucial characteristic for optimizing the memory footprint when working with Big Data frameworks such as Elasticsearch and Opensearch.
In this post, we aim to test this proposition on real world data and find out whether shrinking the embedding size using cohere’s new embedding model, does in fact preserve the retrieval performance.
Background
We conducted this experiment to enhance an existing search system of a customer. Previously, the customer implemented retrieval based only on BM25 which is an effective but limited method for capturing semantic similarity. To take advantage of the semantic similarity, we transitioned to hybrid search combining lexical matching with semantic embeddings.
We needed this experiment because all documents were stored in Elasticsearch, which loads vectors into memory for search. To make sure the system could scale and stay affordable, we focused on keeping the memory use as low as possible.
Why Should I Care?
If you’re building or maintaining a search system at scale, especially on platforms like OpenSearch and Elasticsearch - every byte counts. Embedding vectors often dominate memory usage, and large vectors can limit your scalability or increase infrastructure costs. And obviously, performing vector search (nearest neighbor) is faster the smaller the vectors are.
By showing we can decrease the vector size without significant decrease in performance, we demonstrate a clear path to faster queries and a reduced memory footprint.
Setup
Before storing the documents in Elasticsearch, we applied a preprocessing pipeline that included text cleaning and generating embeddings. This part is crucial, as we aim to make sure the documents are dense and do not include irrelevant information.
For the retrieval, we used hybrid search based on RRF (Reciprocal Rank Fusion) which combines the strengths of semantic and keyword search by blending their rankings. Both the documents and the query were embedded by Cohere Embed 4 model.
Lastly, to improve relevance, we implemented a filtering and reranking mechanism using in-context learning (ICL) with an LLM.

Dataset
We applied this process to documents from multiple clients in the customer success domain. All the documents were processed as described above.
For evaluation, we used real world customer support queries and their relevant documents for retrieval.
Metrics
We used the following metrics to measure retrieval quality:
MAP (Mean Average precision) - Measures how well a ranked list of retrieved items matches the ground truth relevant items. The value ranges from 0 to 1, with 1 indicating that all relevant documents were ranked at the top of the list.
Overall Correct Retrievals - # Number of scenarios for which one of the ground truth documents were retrieved in the top 5 documents.
Results
To ensure a fair comparison, the same test set was used consistently throughout the experiment. The graphs below illustrate each metric as a function of the evaluated scenarios:
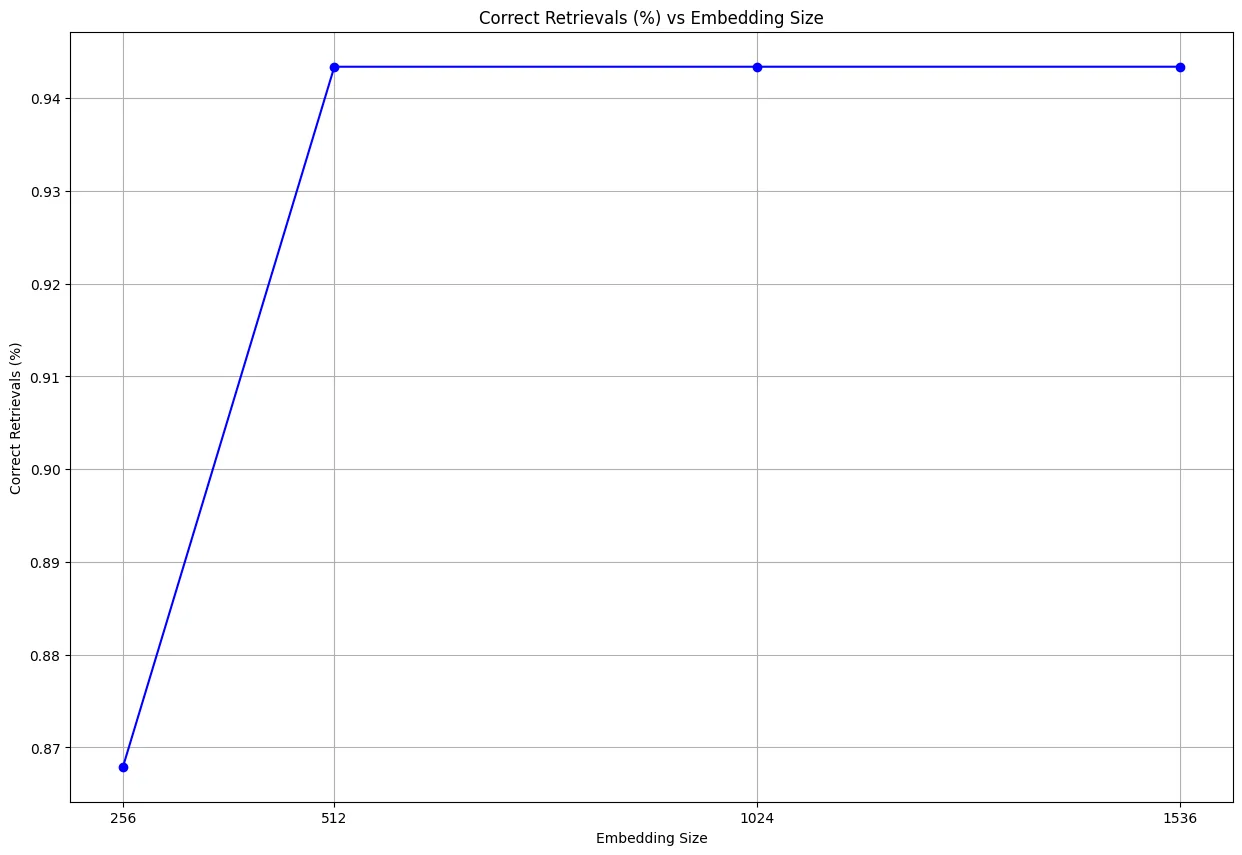
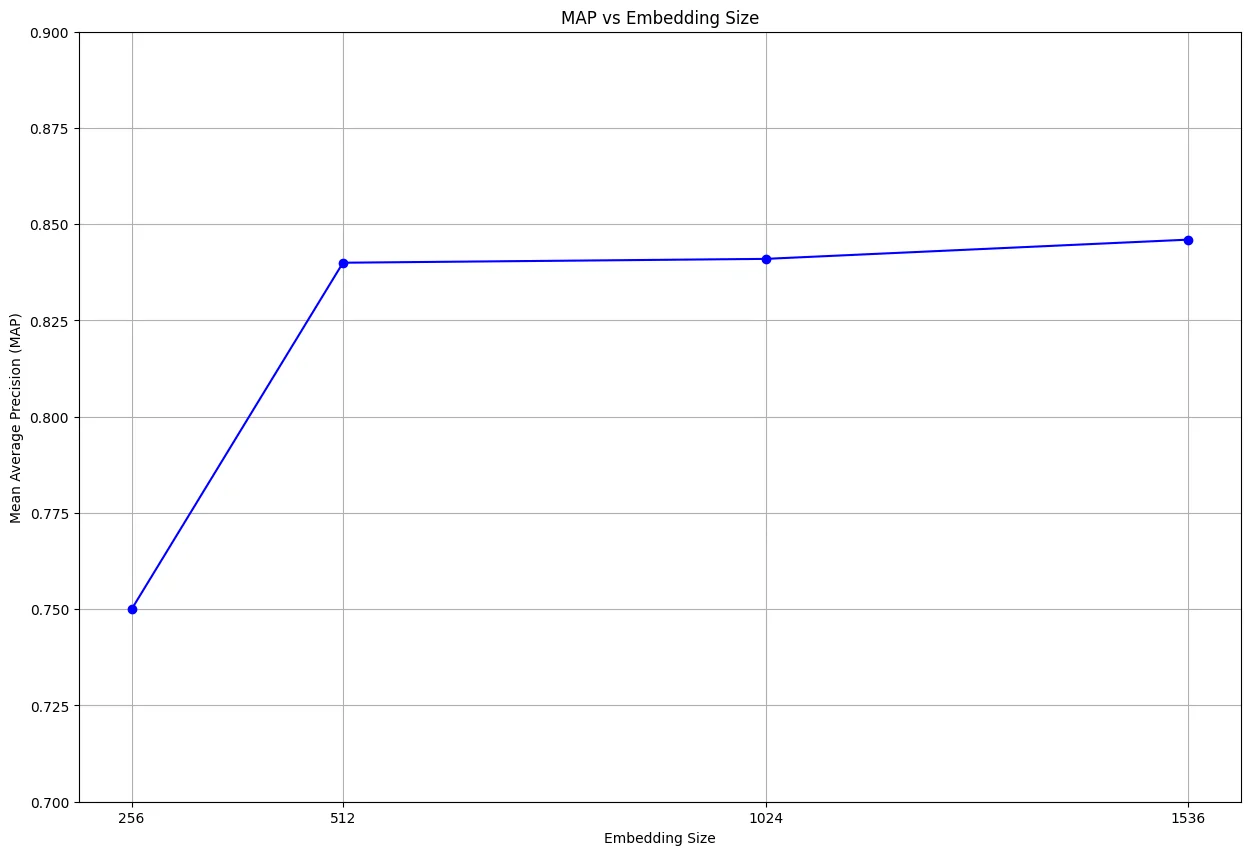
Conclusions
By examining the results, it is clear that we could decrease our embedding size by a factor of 3 while achieving the same performance. As you can see from our experiment, and as Cohere promised, reducing the vector size from 1536 to 512 had almost no impact on retrieval quality. This allowed us to use much less memory in our Elasticsearch clusters and made the system more efficient. With smaller vectors, we can handle more data and save on costs, all without losing search accuracy.

