 Itamar Syn-Hershko
Itamar Syn-Hershko
Apache Hive defined the standard of persisting data on object storage technologies to enable querying. We are now starting to hit the limits of Hive Tables and it’s probably time to discuss what’s next. What are the features we’d want to see in modern Data Lake architectures?

In our introductory post we discussed the typical structure and usual components of a modern data platform.
A very common component of any Data Lake and Data Warehouse implementation is what we often call the “Cold Storage” tier. This is where, or rather how, the vast majority of data is persisted in a cheaper storage solution, ideally in a way that still allows it to be queried. Putting data in “cold storage” assists in reducing the total costs of the data platform and trading off query speed with significantly lower costs.
In this post we are going to focus on that layer of cold storage, understand how it usually works, and try to map the gaps that exist today and offer our wishlist for more modern implementations which will serve the future versions of data platforms.
The best place to start is with the convention most large data platforms in use today are using, often referred to as “Hive Tables”, or the Hive Table Format.
The Hive Table Format
Apache Hive is a SQL engine to query Big Data. It was originally built to translate SQL statements into Hadoop MapReduce jobs, and continued to evolve along with the original Hadoop project, eventually graduating to exist on its own. While Hive as a query engine is mostly dead today, having been replaced by several other more advanced technologies, the key concepts it brought with it are very much still with us today.
To understand the problem Hive needed to solve, we have to remember it is being used in systems where data is persisted on Object Storage technologies such as HDFS, S3, Azure Blob Storage and others. In those technologies, there aren't any indices or any other clues that can help indicate which file (or blob) contains records of interest. Data just resides in many large binary files on storage.
The key idea behind Hive tables is to organize data in a directory structure, so we can read only relevant files based on some partition key. The folder name would be the partition key, and using some table metadata stored in the Hive Metastore a querying engine could only access the “interesting” partitions effectively “pruning” the other partitions from the query execution plan. That way we essentially create sort of an index on the data.
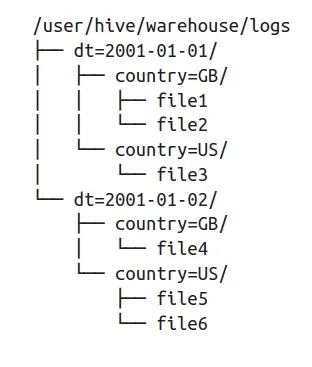
In addition to partitioning, the files in each partition can be broken down further into “buckets”, thus allowing to create some inner sorting of data within a partition, thus potentially further reducing the amount of data files that need to be read and scanned during a query execution.
File Formats
To make querying Big Data efficient it is important to use the right file format on storage. While the naive approach of storing many JSON or CSV files on object storage might sound reasonable and is in fact whats done by most unaware developers, it is the worst possible format to use. A better format would allow to more easily scan the data on queries - and that is what columnar file formats like Parquet and ORC do.
A columnar file format stores all values of a certain column in the same chunks of data on disk. That means reading a column is very very cheap, and this is important because filtering and aggregations are done on columns (for instance using the SQL WHERE operator). This also greatly improves compression, especially for columns with low cardinality. Query engines like AWS Athena rely heavily on these columnar formats for cost and performance optimization.
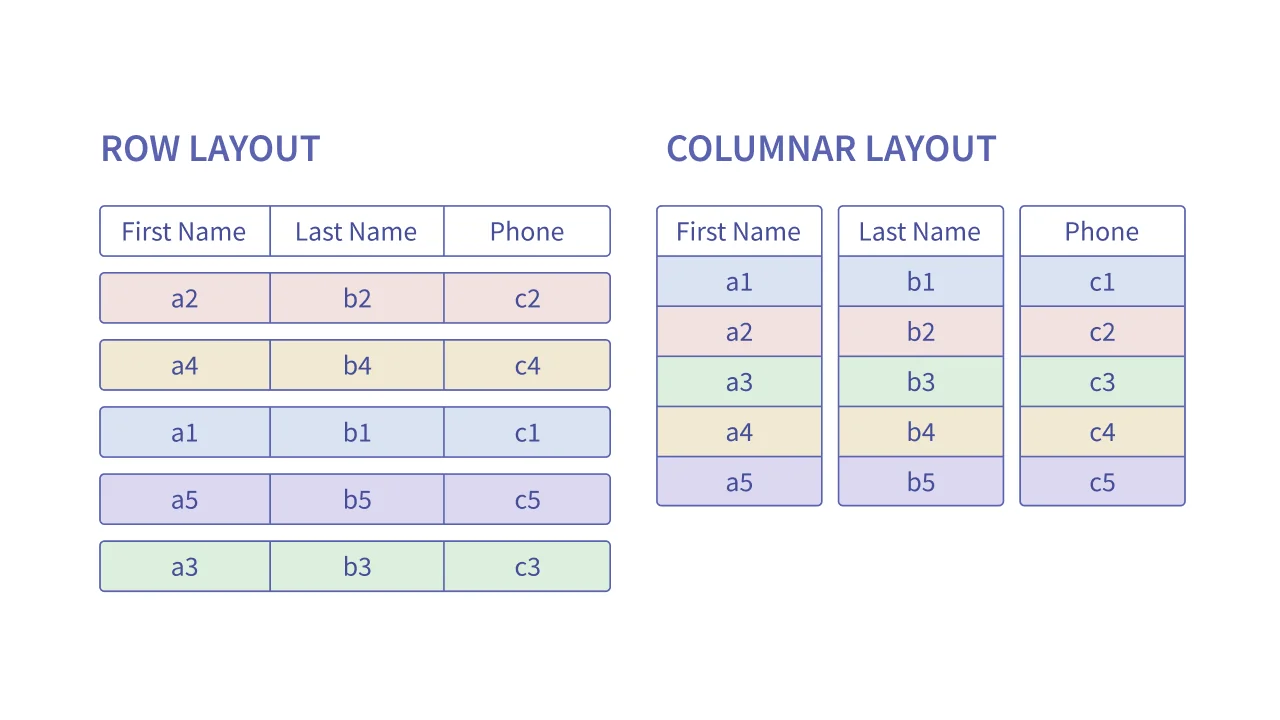
Additional features of the file format like sorting, saving stats on headers, bloom filters even - all help with speeding up scans and queries, since irrelevant files can be skipped over much faster, and sometimes entire query results can be provided from the headers alone.
Hive Tables Everywhere
To summarize, Hive Tables allow effective querying on Big Data by applying a few simple but powerful concepts that make querying data at rest very efficient:
- Partitioning and Bucketing which enable filtering the files being retrieved by the query engine.
- Using columnar file formats, such as ORC and Parquet, to greatly reduce the time needed to scan the files for filtering and aggregating data. Files are both smaller, and better arranged for what query engines need.
- Lastly, optimizing for the right files sizes so the query engine can pull less files that are larger in size. This helps balance parallelism with the actual amount of resources needed to execute a query.
Hive Tables proved to be so effective in querying even Petabytes of data on cold storage, that it became the convention in many systems. As Hive aged, query engines such as Spark, Presto and Trino, were built and eventually replaced Hive as the actual engines being used to query this data..
Where Hive Tables Fail
The very design that makes Hive efficient also makes it fall short in quite a few areas, and those are very well known and documented.
Since data is persisted in compressed files on a cheaper storage tier that doesn’t allow random seeks, updates are deletes are not possible to do, at least not easily. This also affects freshness - if you want to keep files optimized for querying, you have to batch writes thus new data may take some time until it is visible to queries.
The external metastore instance (the Hive Metastore) is required as a database of file pointers. It was originally built to assist with keeping track of large file repositories and to help with housekeeping work, so it is an important addition. However, besides the fact it requires maintenance on its own, it sometimes goes out of sync and requires to actively perform directory listing and refreshes that can become costly processes to perform.
Synchronizing between the file-system and the metastore can’t be done atomically, too. This means it is not possible to synchronize writes, and also another reason why updates and deletes are not natively supported.
Lastly, the partitioning scheme has shortcomings as well.
The layout dictated by Hive supports only one hierarchy of partitions. A very common way to partition data with Hive is based on dates and time of day. If you wanted to add another partition such as tenant ID for example you’d have to either use dates first then tenant ID, or tenant ID then dates. Due to the folder-like partitioning scheme, it is not possible to create partitions that are not in a hierarchy without duplicating the data.
Since partitions are physically on storage, meaning files are actually persisted using a file path, changing a partition scheme is very costly. Repartitioning will involve copying all data and distributing it again on disk. More often than not, partitioning is hard to get right and will usually require changes down the road, even if subtle, and this is one of the biggest pains with Hive today for mature systems.
Our Wishlist for a Modern Data Platforms
Putting the Hive table format aside, lets ask ourselves how the ideal Data at Rest solution would look like?
We collected a list of features and must-haves we believe are crucial for any modern Data Lake and Data Warehouse solution. Since Data Lakes are more frequently dealing with changing data and schemas we
Support for update and delete
The ability to UPDATE and DELETE records within a fileset is critically important. This functionality is often mandated by compliance requirements, such as Europe’s GDPR or California’s CCPA, where customers or users may request their data be removed from a system.
Another very common scenario where updating and deleting records is very handy and a much desired feature is to to fix individual records that have wrong or defect data due to some system bug or missing cleaning procedures.
When using columnar file formats this is going to prove a huge challenge for multiple reasons:
- It’s impossible to just delete or update a single record easily, and a whole file rewrite is going to be required. This is going to prove very hard and costly to do at scale, and will require a lot of time and computational power.
- For those reasons, supporting UPDATE and DELETE operations concurrently is also close to impossible. Due to the nature of the underlying storage and technologies involved, running more than one update process will most likely lead to data corruption or at least inconsistent results; and facilitating locking is very hard to get right.
- No isolation support on the underlying storage systems (object storage) and also file formats, means updates on data while it’s being queried will either fail queries or render unusable results. At the very least that means you can’t run such update procedures as a normal operation.
Support for late arrivals
Pretty much every data platform has data records arriving not in order and sometimes days and months in delay. Late arriving data needs to be added to the right partition on arrival, while still keeping the files and partitions in an optimal state for efficient querying. A modern data platform should overcome this.
Record Deduplication
Often in data architectures, deduplication of data is carried out at the data streaming level as data is being ingested. It can also be written into ETL jobs. However, assuming late arrivals are to be expected in the platform, and efficient DELETE and UPDATE operations exist, depending on the amount of compute resources available, it could prove to be much more efficient for deduplication to be carried out on the storage layer.
More Flexible Data Partitioning
Partition Pruning is the process of completely ignoring full partitions of data during querying, so only data suspected to be relevant to the query is scanned. This is a crucial feature for efficient queries on Data Warehouse and Data Lake platforms.
Oftentimes the partitioning scheme is defined early in application life, much before the real challenges and even real data are encountered. Once the application is deployed and used, the weaknesses in the selected partitioning scheme start to surface, and in an ideal data platform we’d like them to be much easier to change. Ideally, changing a partitioning scheme should just be a matter of executing a simple ALTER command without significant side effects.
Non-hierarchical partitioning schemes
Today, partitions in most systems are usually hierarchical (year, month, day; sometimes tenant ID, year, month, day; and so on). But in truth, the data model for most systems is much more sophisticated than that, and there could be many other useful partitions that could be used if it was possible to do so efficiently.
As long as the partitioning scheme is relying on the Hive Table Format’s approach, meaning doing it in a folder-like structure, adding another partition means either adding another partition level when the data is orthogonal, resulting in smaller files and requiring more parallelism; or copying the entire data several times to introduce the several partitions on the storage layer.
Schema Evolution
The ideal modern data platform should allow for the data schema to non-disruptively evolve as time progresses. This may include, for example, adding/dropping/changing columns. The coupling of data and metadata on the Hive Table Format’s approach means many changes to the table structure have to result in rewriting the actual data files on the object storage.
This is especially important when executing some operations that an be considered “unsafe”, e.g. when multiple partitions are involved in a single operation, or when changing a column position or its data type. Without proper handling of the table metadata, which is handled in a safe and transactional manner, existing code and queries will break.
Data Validation and Quality Controls
A typical issue with all data platforms is garbage-in garbage-out - the lack of proper data cleansing and validation often leads to wrong answers to queries and even wrong decisions being made.
Data errors can of course also expose your entire pipeline to crashes and unexpected behaviors, so it’s also a matter of stability and operations peace of mind.
The ultimate data platform will be sophisticated enough to provide controls for data validation and quality assurance. We could expect it to enforce rules on fields (RegEx validation; timestamp fields should not have 80 year-old date; etc) , and even avoid regulatory issues by preventing PII data from being stored except from in designated fields.
Point-in-time View
Having a point-in-time view of data is another capability that is important for change management or disaster recovery. The ability to “go back in time” and query and view data as it looked like on a specific date and time, including data that has since been deleted, can significantly improve resilience and software development pace.
Views and Materialized Views
Like with any database, the ability to create Views and Materialized Views so query parts can be reused, and even better - precomputed, is a significant boost to many workloads. The better the support for those, the better and more performant the data platform will be.
Great Operations Story
Multi-cloud (and multi-region within the same cloud), easy maintenance, low-touch for operations, good monitoring for any housekeeping tasks - are all important to ensure smooth operations and good overall health. Those are more than just nice to have - but the list is too long to put it all here. A great operations story is critical for any technology to succeed, especially one that is going to be in charge of huge amounts of business critical data.
Summary
The Hive Table Format is a great entry point for an in-depth discussion on data storage formats applicable for Big Data platforms, which can also enable efficient querying.
Hive defined a lot of how we do things at present day, but it has aged and requirements have evolved over the years. It is probably a good time to find a suitable replacement, and keep pushing the envelope.
In the next posts we will dive into several other table formats which come as successors to the Hive table format. Stay tuned!

