 Itamar Syn-Hershko
Itamar Syn-Hershko
Apache Iceberg is a new table format for storing large, slow-moving tabular data. It is designed to improve on the de-facto standard table layout built into Hive, Presto, and Spark. We believe Iceberg has huge potential of changing the way we do Data Warehousing and you should check it out!

Cloud Computing today is accessible by everyone: anyone can launch a EC2 instance on AWS or write entire systems using Serverless technologies without launching even a single VM. The on-going competition between cloud giants AWS, Google Cloud Platform and Microsoft Azure keeps bringing prices down and creating your own full-scale cloud solution is cheaper than ever.
Data Warehouses, however, are by definition not going to be cheap to create and operate. Today, only rich companies or truly data-driven companies can afford to put efforts into launching a real data warehouse. Even fewer are the organizations that run data warehouses in really amazing scales.
It is no surprise then that it is companies like Google, Uber, Netflix and Facebook that are driving innovation in the Data Warehousing space. And by Data Warehousing we mean a solution or platform which let's you run ad-hoc queries on large volumes of data (so called "BigData"); efficient storage of this data; and cataloguing the data in a way that makes it easy to later append or update it.
You shouldn't underestimate the importance of data cataloguing. Any real-world data warehouse is going to eventually deal with one serious devil - data has many faces, and none of them will ever stay the same. Even a well thought-out schema will eventually change in some way (new fields added; data types changed; re-partition is needed; etc) and when that happens - are your data warehouse platform and data catalogue equipped with making such a change easily?
Schema evolution is just the tip of the iceberg; huge amounts of data bring unique set of challenges that we have only recently started to truly understand. And for those types of challenges new set of tools need to evolve. Enter Apache Iceberg.
Apache Iceberg is a new table format for storing large, slow-moving tabular data. It is designed to improve on the de-facto standard table layout built into Hive, Presto, and Spark. Originally created by Netflix, it is now an Apache-licensed open source project which specifies a new portable table format and standardizes many important features, including:
All reads use snapshot isolation without locking.
No directory listings are required for query planning.
Files can be added, removed, or replaced atomically.
Full schema evolution supports changes in the table over time.
Partitioning evolution enables changes to the physical layout without breaking existing queries.
Data files are stored as Avro, ORC, or Parquet.
Support for Spark, Hive, and Presto.
The idea behind Iceberg is to solve the way we think (and maintain) of files and partitions holding data in our BigData repositories. Be it S3 or HDFS, today's methods of storing data, managing it's schema, supporting updates and maintaining partitions - have too many pitfalls and screeches that it is time to learn from our collective experience and create something better.
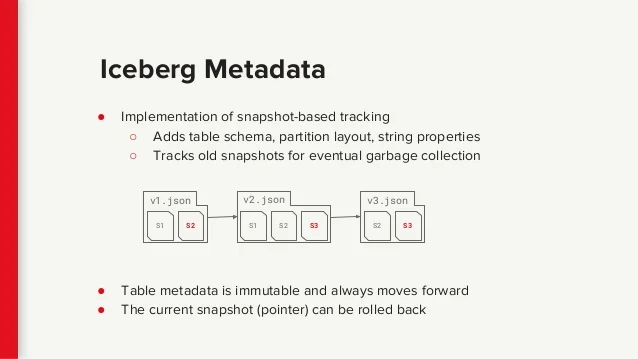
While Apache Iceberg is still Work In Progress, you should definitely keep an eye out for it, and even learn more about it and get involved on this early stage. We believe Iceberg has huge potential of changing the way we do Data Warehousing, to a point where it's easier, faster, and more economical for all to use.
Here are some links to get you started:
Apache Iceberg on Github: https://github.com/apache/incubator-iceberg
The Iceberg table spec (Google Doc collaborative effort): https://docs.google.com/document/d/1Q-zL5lSCle6NEEdyfiYsXYzX_Q8Qf0ctMyGBKslOswA/edit#heading=h.vga9bjlv1x2e
An interview with Ryan Blue from Netflix, the person behind Iceberg: https://www.dataengineeringpodcast.com/iceberg-with-ryan-blue-episode-52/

