Itamar Syn-Hershko
Itamar Syn-Hershko
Our Presto Elasticsearch Connector is built with performance in mind. We leveraged our deep knowledge of both Elasticsearch and Presto to build this production ready, enterprise grade, connector that is up for any challenge. Here are some of the use-cases it is being used for.
Presto is a high performance, distributed SQL query engine for BigData. Slowly but surely, it is becoming the de-facto standard for implementing cost-effective Data Lakes and Data Warehouses - mainly thanks to its ability to query huge amounts of data in what we often call “interactive time”.
Elasticsearch is a real-time search and analytics engine, and it is the core product behind the well-known Elastic Stack. It is mainly used for log analytics and for creating interactive dashboards to browse and drill-down into data, usually events or time based. Response times with Elastic are in most cases subsecond, thus it is being widely used for ad-hoc data investigation and often using an interactive UI or Kibana dashboards.
More often than not we find ourselves implementing BigData architectures that include those two technologies. Presto is usually deployed for what we call the “cold layer”, and Elasticsearch for the “hot layer”. In most systems, real-time access isn’t required for the lion’s share of the data where the main concern is keeping costs low; and so S3 and Presto are a great fit. Usually ultra-low latency queries are only required for a portion of the data, and that is where Elasticsearch, which is more hardware demanding and hence costler, really shines.
And this is where things start being really interesting.
Connecting Presto with Elasticsearch
One of Presto’s core design principles is the use of Connectors. A Connector controls the data flow from a data source to Presto (and back), and is responsible for representing the data source data as tables, columns and rows to Presto - even if columns and rows is not really the shape of that data in its source.
Connectors abstract Presto’s data access layer, thus allowing it to query virtually any data source. The Connector implementation is responsible for making sure the data flows correctly, and even more importantly - efficiently.
Since we see Presto and Elasticsearch running side by side in many data oriented systems, we opted to create the first production ready, enterprise grade, Elasticsearch connector for Presto.
Here are some of the more common use cases this connector is used in. Each of the use-cases presented below really deserves it’s own blog post, but this is just to give you an idea of what is possible with our Elasticsearch connector for Presto.
Use case: Temporary responsive “views” on BigData
Many people know Elasticsearch thanks to Kibana - a widely used visualization tool for Elastic, which is also part of the Elastic stack. It is usually being used by analysts to drill down into data using visualizations and dashboards. The ability to have subsecond responses to queries from Elasticsearch makes Kibana users very happy, as dashboards are always very responsive.
Many BigData investigations involve only small portions of the data. Out of Petabytes of records, usually when filters are applied the dataset shrinks to several millions or billions of rows, and that is where more ad-hoc exploratory tools are becoming handy.
The Elasticsearch Presto connector allows to write the result of any query into a temporary “table” (read: index) on Elasticsearch, and then Kibana can be easily used to further explore the data, find unknowns and sharpen the queries. This allows to query S3 or HDFS using Presto, and create a Kibana-browsable temporary view of the results.
This is how the Connector essentially allows to facilitate “views” which are subsecond queryable on top of BigData.
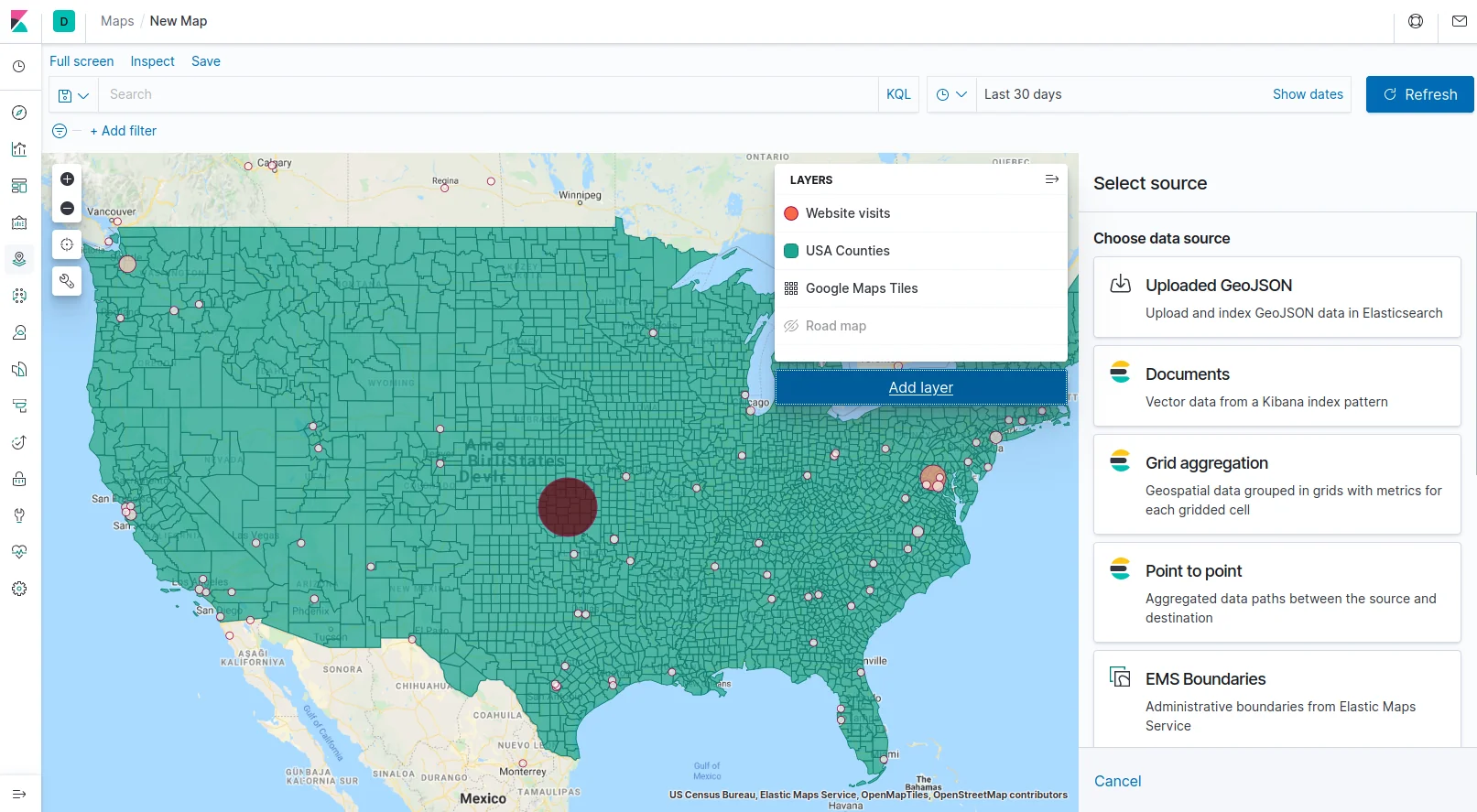
Use case: Real-time and interactive Maps for BigData
Elastic Stack is really good at handling geospatial data. Elasticsearch serving as the data backbone and Kibana as the UI on top of it are feature-rich when it comes to querying data containing geo-points and geo-shapes.
Many of our customers store and query geo-spatial data. They use geo-spatial query criteria along with other more standard filters to find the interesting records in their mountains of data, but just as in the previous use-case - those can still be mountains of records to sort through.
We found it very useful to create “views” in Elasticsearch just as before, but this time our purpose is to leverage Kibana’s Maps app to visually and interactively browse the geo-spatial data in real-time. This proved to be a rather neat approach when the data and the queries are really geo-spatial oriented.
Use case: Enrichment on query-time from other data sources
A common challenge with Elasticsearch is data modeling. Elasticsearch is designed to be truly effective for logs and events where writes are append-only, where no updates occur to previously written data. But what happens when you need the event log to actually reference data from your live system - e.g. the person’s name as it appears now in the system, and not as it appeared when the event occurred and logged.
What if you could search and read the events from Elasticsearch, but then enrich the results in read-time from your current golden source of data (SQL Server, Postgres, MySQL, Cassandra, etc)?
One of Presto’s most exciting features is Federated Queries - the ability to execute a single SQL statement that will run and join data from completely different data sources. We can now use Query Federation to execute full-text search on Elasticsearch to find logs and events, and then join them with the reference tables in MySQL for example to enrich them with the most recent values for some fields.
Use case: Join on Elasticsearch indexes
Elasticsearch, being a distributed document store that can’t beat the CAP Theorem and at most times favors Partition Tolerance over Consistency, by design does not (and cannot) support joins.
Using Query Federation again, with our Connector you can now execute SQL similar to this and get a valid response:
SELECT l.timestamp, u.user_name, l.message FROM logs l, users uWHERE l.userId = u.id
ORDER BY l.timestamp DESC
This of course also enables self-joins on the same index, or joins between indexes on different clusters. The indexes being joined don’t have to be on the same cluster.We did not build this connector in order to facilitate joins with Elasticsearch, nor do we recommend doing this in the first place, but when it is absolutely necessary - yeah, our Connector enables that, and quite elegantly.
Use case: Ingest data into Elasticsearch from Kafka, Kinesis or Pulsar
While there are plenty of ETL tools available, in any shape, color and form - sometimes it makes sense to reuse the pieces you already have and avoid adding more new components to your already complex system.
Presto is often used as an ETL tool. Granted, it’s not meant for long running jobs - we have Spark for that. But for any short data copy operations from X to Z, Presto is actually a great fit.
What if you could just write an SQL statement like this to ingest data from Kafka to Elasticsearch?
INSERT INTO elasticsearch.tweets-2020.05.01
SELECT * FROM kafka.tweets;
Now you can! This SQL will use the Kafka Connector (LINK) to read records from the Kafka topic `tweets`, and then write them into the `tweets-2020.04.19` index in Elasticsearch. As simple as that.
Performance
Presto does have a built-in connector for Elasticsearch, but that connector is very limited in features. For example, it doesn’t support recent ES versions and doesn’t support writing into Elasticsearch.
But most importantly, it is a very basic implementation that doesn’t take into account the internals of both Presto and Elasticsearch and wasn’t built to be optimized for running queries on both.
Our Presto Elasticsearch Connector is built with performance in mind. We leveraged our deep knowledge of both Elasticsearch and Presto to build a connector that is using the right APIs in the best possible way. The result is a production ready, enterprise grade, connector that is up for any challenge, for the use-cases mentioned above and many others. You will find some numbers at the bottom of the post.
Want to give it a spin?
This connector is part of our Premium offering, provided to our customers as part of our consulting engagements or managed BigData services. Reach out to us and we can set up a meeting to discuss the best way to collaborate and give you access to our connector.
Performance numbers
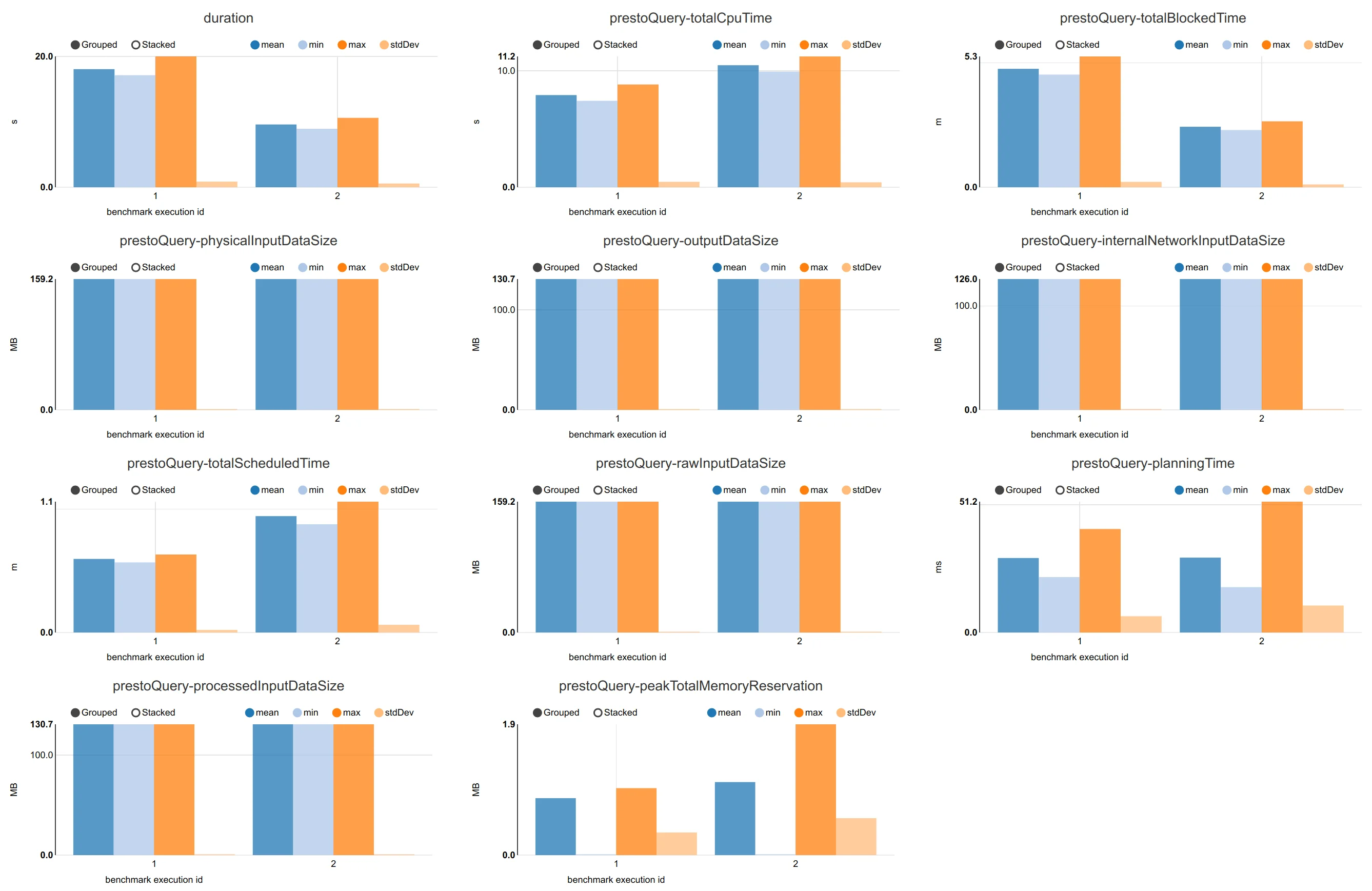
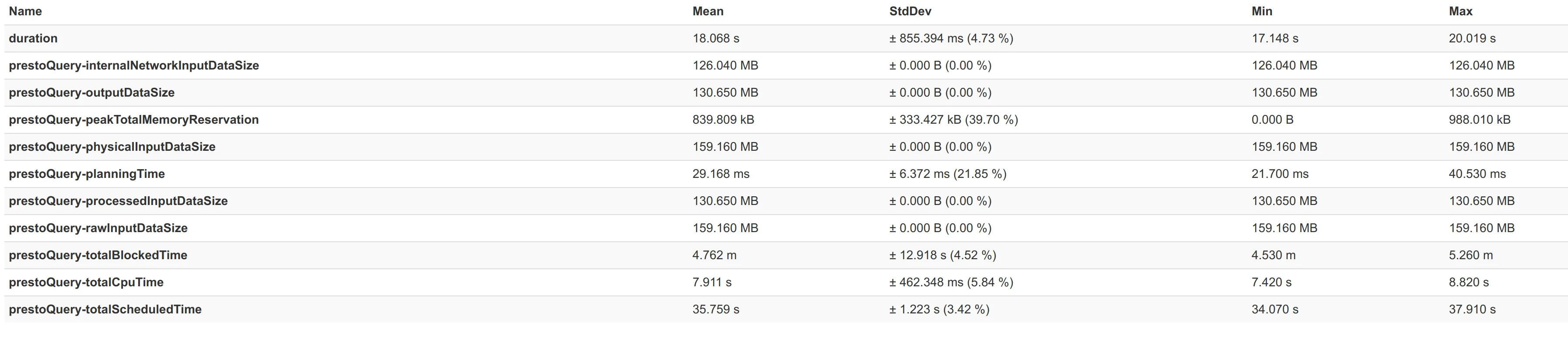
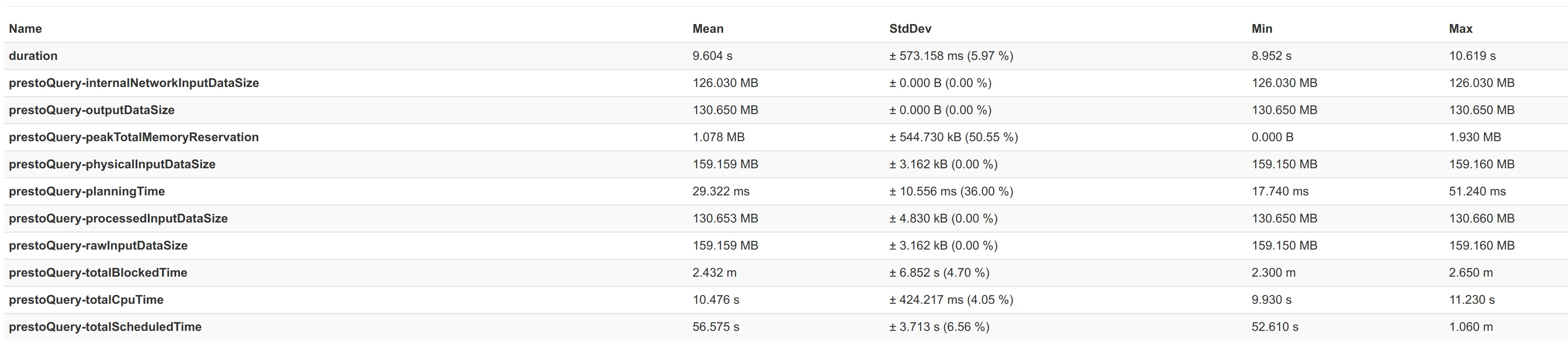
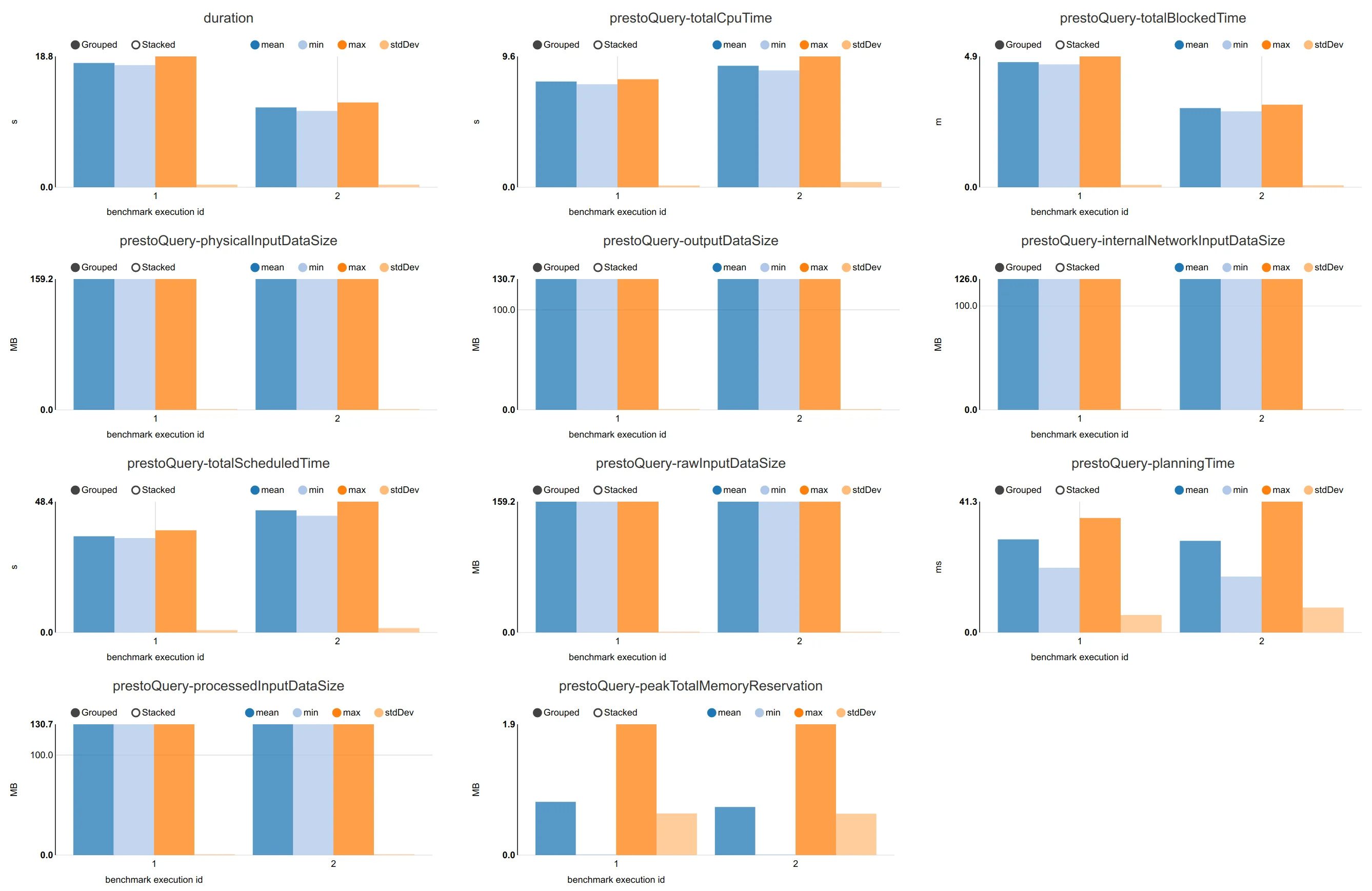
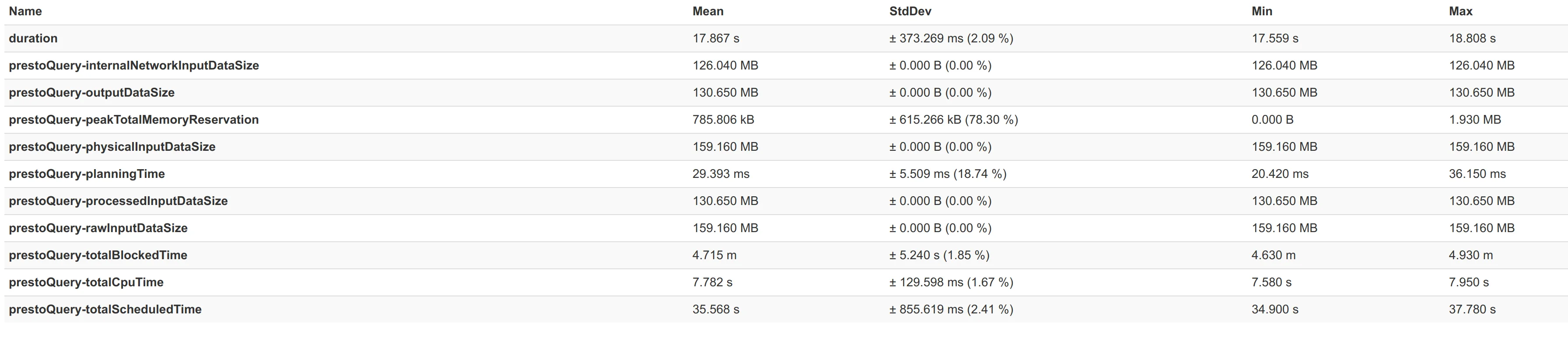
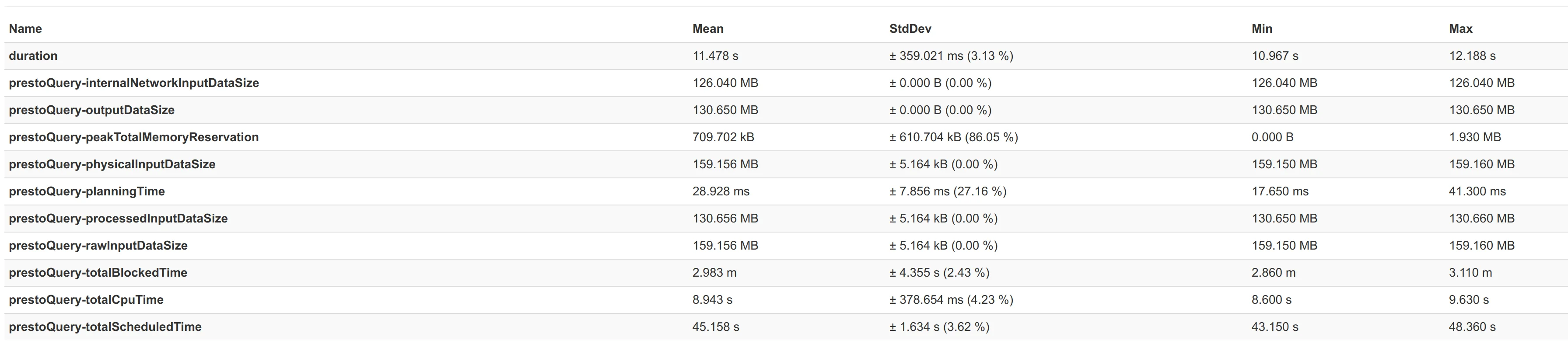
Just in order to give some idea of how good the connector really is, attached here are some performance numbers from a benchmark we did with benchto between the Elasticsearch connector from Presto 329 and our connector.
We benchmarked two scenarios - one with a 3-node cluster and the second is a 5-node cluster. First shown is the comparison, where you can see a ~2x better query performance on average, and following that the actual benchmark numbers - first for the Elasticsearch Connector from Presto 329 and then for our Connector.
For a 3-nodes Elasticsearch nodes:
For a 5-nodes Elasticsearch cluster: