 Itamar Syn-Hershko
Itamar Syn-Hershko
Delta Lake (originally developed by Databricks) has become a household name when it comes to modern cloud table formats. But is it the right one for you? Learn more in this detailed review.

In the latest edition of our modern data platform post series, we are going to put the Delta Lake project under the microscope, looking first at its history, before delving into its architecture and features. Delta Lake solves similar challenges to the other cloud table formats we’re exploring in this series (Apache Hudi and Iceberg). In many ways it’s an evolution of Apache Hudi, but has a lot of additional features and is making fast advancements in this space. It’s absolutely a technology to consider , whether you are looking to upgrade an older Hive-based solution, or create a greenfield Data Lakehouse solution.
What is Delta Lake?
Delta Lake was launched in early 2019 by Databricks, an Apache Spark company, as a cloud table format built on open standards and partially open-source.
The idea behind Delta Lake was to support the very frequently requested features in the modern data platforms ecosystem, or should we say Big Data - data mutability, point in time view of data (aka Time Travel), ACID guarantees and concurrent writes, and more. We discussed those features and why they are so requested and were hard to get right in our previous posts in the series.
At the time of its launch, Delta Lake was released with some features behind a “paywall” and you had to be a Databricks customer to use them in their Databricks Platform. It was only in 2022 that Databricks agreed to fully open source the entire product and contribute future enhancements to the Linux Foundation.
Even as an open source platform, Databricks are investing and aligning Delta Lake features so it aligns with their other products and cloud (and understandably so). Additionally, because it’s maintained by a large and well-known commercial entity, Delta Lake is likely to have more development effort committed than other data platforms technologies (esp. that it is now an integral part of Delta Live Tables that is yet another hot product from Databricks). However, Delta Lake isn’t alone as a commercial open source product in the data lake space - Apache Iceberg and Apache Hudi have been doing this for some time already, too.
Delta Lake is mostly a Java and Apache Spark effort, but it is indeed developed through an open standard so there are, and will be, integrations from other languages and tools, for example the Delta Lake Rust interface.
Delta Lake Architecture
Like Parquet, ORC, CSV and JSON, Delta Lake is a file-based format or to be rather more exact - a table format. The main idea has always been to make listing files in cloud blob storages faster (and cheaper at the same time).
When building Delta Lake, Databricks took the same concepts of Hive table format that we’ve seen before such as partitioning through paths, and implemented a lot of improvements and fixes based on lessons learned from Apache Hudi and Apache Iceberg (nota bene, many if not most changes to the latest version of the Connector API in Apache Spark 3 have been contributed by the former Netflix engineer, Ryan Blue who created a commercial entity behind Apache Iceberg, Tabular).
Delta Lake absolutely satisfies many items on our wishlist for modern data architectures. These are things like ACID transactions, mutable data, a point-in-time view (“time travel”), integration with many tools and technologies, and more.
Below are some highlights and architectural nuances unique to Delta Lake.
Hive-like Table Format
Similar to Hudi’s Hive format, Delta Lake also creates a transaction log. This transaction log maintains a record of all operations requested on data, and the table metadata, as well as pointers to the data files themselves (Parquet) and their statistics (in JSON-encoded metadata files). Those statistics are important and deliver huge benefits for query performance. It also maintains a record of table versions which facilitates Delta Lake’s point-in-time view, called Delta Time Travel.
The statistics recorded by the transaction log are the maximum and minimum values for each column found in the actual data files, null counts, etc that allow for metadata-only queries like counts or data skipping (skipping data files at load time if they do not meet the requirements of a query). This means that complex queries can be processed in much less time and cheaper (we’re in a cloud environment after all where every operation counts). This is known as data skipping.
Most importantly, accessing the transaction log (“manifest files”) using Apache Spark, PrestoDB, Trino and many other supported query engines is very straightforward. Querying and writing to a Delta Lake powered data platform is very easy today and does not require any specific knowledge of the inner workings of Delta Lake. The query engines will do all that for you.

This table format allows to support updates and deletes, therefore CDC (Change Data Capture) is fully supported to sync OLTP databases into the data lake; and also shallow clones, which helps with creating derivative tables easily - cloning PBs of data easily and cheaply just like a “git branch” operation.
Medallion Architecture (Bronze, Silver, and Gold Tables)
Databricks, the company behind Delta Lake, promotes a data maintenance strategy often referred to as Medallion Architecture (Bronze-Silver-Gold). Those are conceptual, logical tiers of data which helps categorize data maturity and availability to querying and processing.
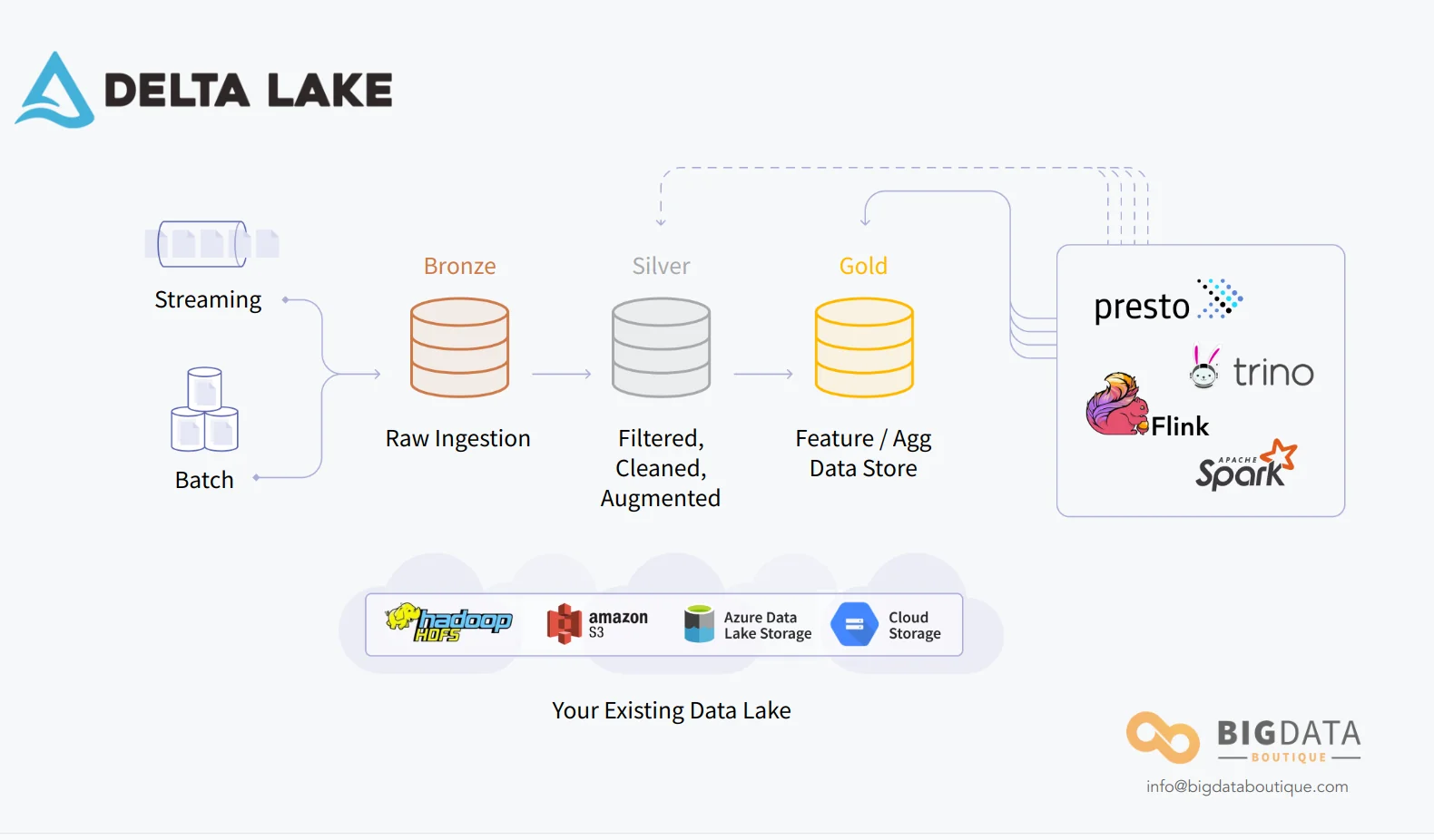
Standard query engines and processing techniques can be used on any of the tiers, and also for moving data between the tiers. The main idea behind this approach is to differentiate between different data qualities, and to create higher tiers of data by cleaning, enriching and aggregating data from lower tiers.
The Bronze Tier consists of tables that hold raw data, immediately-post ingest. This data will most likely be from various sources, but usually it will be unaltered from its source. Data can be ingested into this tier via either streaming or batch processes.
Data held in the Silver tier has been refined, either via ETL processes or data preparation. Typically Delta Lake tables in this tier will have been enriched and possibly joined with other tables and sources to create a more customized and insightful view of the data.
Gold tier data is full of meaningful and actionable insights, mainly because the Delta Lake tables on that tier are fully prepared. These tables act as your feature store and represent actionable data, and are directly queryable by analysts and even end users.
Data in any of the tiers is queryable, but Silver and Gold tiers is data that is really ready for consumption.
Copy on Write
Delta Lake only offers Copy on Write (CoW) with no support for Merge on Read, (although this capability could be available in future releases). CoW with Delta Lake sees data stored in a Parquet format; every time the data is updated, a new version of the updated data is created (leading to even more parquet part data files under the table’s data directory). General opinion and common sense dictate that CoW is far better for query-heavy use-cases.
Delta Lake Schema Architecture
Delta Lake was designed to mitigate data loss and optimize performance. As such, there are several elements of schema architecture that are unique to it as a platform. Here are the main cornerstones you need to be familiar with.
Schema Evolution
Schema Evolution on Delta Lake allows users to change a table’s existing schema to accommodate data that has changed over time or is added to the table. This is important for tables in the Gold tier as it’s most commonly needed for append and overwrite operations. This allows for the creation of additional columns that were not previously described in the schema.
It’s also possible to have an implicit schema definition with Delta Lake by using the mergeSchema option in a query. This will transfer all of the columns to the target table on write, and can also add nested fields. Caution must be exercised while using MERGESCHEMA because you could end up with duplicate data and unnecessary columns without proper planning.
Schema Enforcement
The Delta Lake architecture contains a built-in failsafe to guarantee data quality, which is called Schema Enforcement. This prevents writes to a table that do not match its schema and can be altered to enforce against different conditions such as differences in columns or differences in data types. If data is outside of the pre-existing schema, then it is simply recorded as a null value.
Schema Enforcement is useful for data analytics, machine learning, and business intelligence as it gives a uniformity of data to prevent existing algorithms or dashboards from erroring.
Delta Lake Features
As with the architectural section, Delta Lake shares common features with other data lake products of equal repute. However, Delta Lake also delivers some stand-out features which differentiate it from the crowd. We’ll explore these below.
Delta Live Tables
Delta Live Tables is a framework which allows to declare transformations on datasets and specify how records are processed through query logic. It is used for building reliable, maintainable, and testable data processing pipelines. As stated by the documentation - “Instead of defining your data pipelines using a series of separate Apache Spark tasks, you define streaming tables and materialized views that the system should create and keep up to date. Delta Live Tables manages how your data is transformed based on queries you define for each processing step. You can also enforce data quality with Delta Live Tables expectations, which allow you to define expected data quality and specify how to handle records that fail those expectations.”
You can draft a data quality constraint using either Python or SQL. The constraint consists of a descriptor, an invariant, and an action to take for any record that fails the invariant. It is based on the data expectations feature in Delta Lake, see the CHECK constraint for example. Actions that can be taken on records that don’t meet the invariant are drop (prevention of procession of a given record), fail (stops any process as soon as a record fails to meet an invariant, with table updates being rolled back), and retain (keep the records which fail to meet the invariant).
Delta Live Tables also respects any preexisting dependencies which may exist between tables to prevent you from having to rewrite any ongoing queries. This is a great feature for developing data pipelines and ensuring that as your data progresses through Bronze, Silver, and Gold tiers (see above) it improves in quality. It also allows for automated testing and can be run in either batch or streaming mode.
Generated Columns
Whilst generated columns are nothing new for databases, having them in a Data Lake solution is rare. They are columns whose values are generated by Delta Lake based on functions defined by end-users. Typically you would use the Generated Columns feature in your Gold tier of data, as it serves to provide precise insights from a range of sources and then writes that insight to a table.
Identity Columns, a type of Generated Columns that assign a unique value for each row, are also available and supported in Spark 3.4, that opened up the feature to other cloud table formats.
You can create Generated Columns on Delta Lake using either SQL or the DeltaTableBuilder API.
Cloud Agnostic
Delta Lake is just an open-standard, and then an implementation of it, and as such it isn’t constrained to a cloud platform. Delta Lake is available on Databricks’s platform on all major cloud platforms, but it’s also possible to leverage Delta Lake without requiring a Databricks installation, or on any niche cloud or private data center.
Data Skipping and Compaction
As mentioned earlier, Delta Lake’s data skipping is made possible by the use of a transaction log. This narrows down the searching time of a given query, as all of the records are described in the log and can be quickly narrowed down based on their suitability for the query. If that feature wasn’t enough, Delta Lake further enhances performance via compaction.
Compaction is triggered by running a simple OPTIMIZE command on Delta Lake. This feature condenses numerous small Parquet files into a single large Parquet file, as it’s faster to query one large file than many small files.
What’s more, because of Delta Lake’s ACID compliance, the OPTIMIZE command can be run and executed at the same time that users are querying the table. To top it all off, this function can be run automatically to automatically regulate Parquet size and continuously optimize query performance.
Data Skipping is a major feature of any modern data lake and a lot of effort is put in order to innovate and find more ways to do this efficiently, for various use-cases. For example, in Delta Lake z-order indexes are used for data skipping as well.
Delta Sharing
As a general rule, you can’t access Delta Lake tables outside of Databricks runtime because ingestion depends on the Delta ACID API. However, Databricks have introduced Delta Sharing, which might change all that. The goal of the Delta Sharing feature is to allow the sharing of live data without having to make a copy, across a variety of clients whilst maintaining total security.
At its core, Delta Sharing is a REST protocol that allows limited access to part of a cloud-hosted database. It uses traditional cloud-based storage, like AWS S3 or Google Cloud Storage, to facilitate the sharing or transfer of datasets. Security is governed by token-based authentication, although other verification methods are under development (e.g. Databricks Unity Catalog).
One of the most interesting aspects of Delta Sharing is that you as the data provider can choose the version or how much of the dataset you wish to share. This sharing capability is significantly more cost-effective than traditional data transfers, and also allows for global collaboration on big data between organizations. Use-cases in financial services, vaccine development, and space exploration are already being seen.
Conclusion
There’s no arguing that Delta Lake is a fantastic tool with some incredible features. Unfortunately, there are some aspects like the lack of support for Merge on Read that let it down. But overall, its unique features are its greatest differentiator. Delta Sharing and Data Skipping do not exist with the same scalability elsewhere on the market. These combined with Databricks’ enterprise support organization makes Delta Lake a great option for large companies.
While Delta Lake is indeed open-source, its most common usage is through the Databricks cloud product. Regardless, it is very easy to start with and the fast development pace is very promising.
Stay tuned for our next installment in this series - reviewing Apache Iceberg, and then comparison of Apache Hudi, Apache Iceberg, and Delta Lake.

