 Itamar Syn-Hershko
Itamar Syn-Hershko
Apache Hudi is the open-source data lakehouse platform that brought record-level updates and deletes to S3-based data lakes. This guide covers Hudi's architecture, table formats, query types, and what changed in Hudi 1.x.

Apache Hudi (Hadoop Upserts Deletes and Incrementals) is an open-source data lakehouse storage framework that enables record-level insert, update, and delete operations on data stored in cloud object stores like S3, GCS, and Azure Blob Storage. Originally built at Uber to handle CDC ingestion into their 100+ petabyte data lake, Hudi was the first technology to make mutable operations practical on immutable storage - paving the way for modern data lakehouses as we know them.
This is part of our series, Architectures Of A Modern Data Platform
Updated March 2026
This article was originally published in March 2023. It has been substantially updated to cover Apache Hudi 1.x - including non-blocking concurrency control, the LSM-based timeline, multi-modal indexing, partial updates, and the DeltaStreamer-to-HoodieStreamer rename. We also added a Hudi vs Iceberg comparison table and a production deployment section.
A Short History of Apache Hudi
Hudi was developed at Uber starting in the early 2010s and went into production in 2016. At that point Uber's data platform managed over 100 PB of data supporting trips, riders, and customer operations, processing over 500 billion records per day. The core requirement was straightforward but technically difficult: feed changes from relational SQL databases via CDC or binlogs into a data lake, including updates and deletes - not just appends.
Uber submitted Hudi to the Apache Software Foundation in 2019 as open-source software. Since then, major data-intensive organizations have adopted it - Walmart, Disney+ Hotstar, ByteDance (powering TikTok's data infrastructure), Notion, Alibaba Cloud, and Amazon (which offers Hudi as a first-class option in EMR and Glue).

As covered in our introductory post on modern data platforms, we don't draw hard lines between data lakes and data warehouses - when implemented properly, their architectures converge. With that framing, let's evaluate how Hudi measures up against the requirements of a modern data platform.
The Challenges Hudi Solves
Hudi originated from the requirement to feed changes from traditional relational databases into data lake storage for long retention and analytical queries at scale.
At the core of the Hudi project is the capability to connect any relational database to object storage (S3, HDFS, GCS) via CDC or binlog - the standard ways of capturing data changes in SQL databases. Since change streams include row updates and deletes alongside inserts, this is not a trivial problem. Before Hudi, there was no straightforward way to apply record-level mutations to data on S3. Teams either built brittle custom solutions or simply avoided the problem, accepting stale snapshots instead.
That is why Hudi matters: it made mutable data lakes possible and practical. Today, any commonly used query engine supports querying Hudi tables - Trino, PrestoDB, Spark, Flink, and more.
Common Apache Hudi Use Cases
Given Uber's initial development of Hudi, it addresses several use cases where traditional data warehouse and data lake platforms have gaps.
Near real-time data ingestion. Hudi doesn't provide true real-time ingestion, but it gets closer than most data lake platforms. Its HoodieStreamer tool (formerly DeltaStreamer, renamed in Hudi 1.x) allows easy scale-out to include more and more sources. Operations like Upsert for RDBMS sources provide resource-efficient alternatives to full bulk-upload ingests.
Incremental processing. Traditional data architectures often drop or mishandle late-arriving data. As ETL pipeline complexity grows, processing time and event time diverge. Hudi addresses this with dedicated mechanisms for consuming only new or changed data, allowing processing schedules to run on much shorter increments rather than full-table scans.
Streaming-first architecture. Hudi brings data streaming principles to data lake storage, enabling faster ingestion than traditional batch architectures. Combined with incremental processing, this allows building pipelines that are both faster and cheaper than batch-only approaches - without requiring always-on server resources.
Schema evolution. The ability to alter data schemas on the fly is critical for evolving data platforms. Hudi leverages Avro for dynamic schema changes using schema-on-write, which prevents pipeline failures from backward-incompatible schema changes.
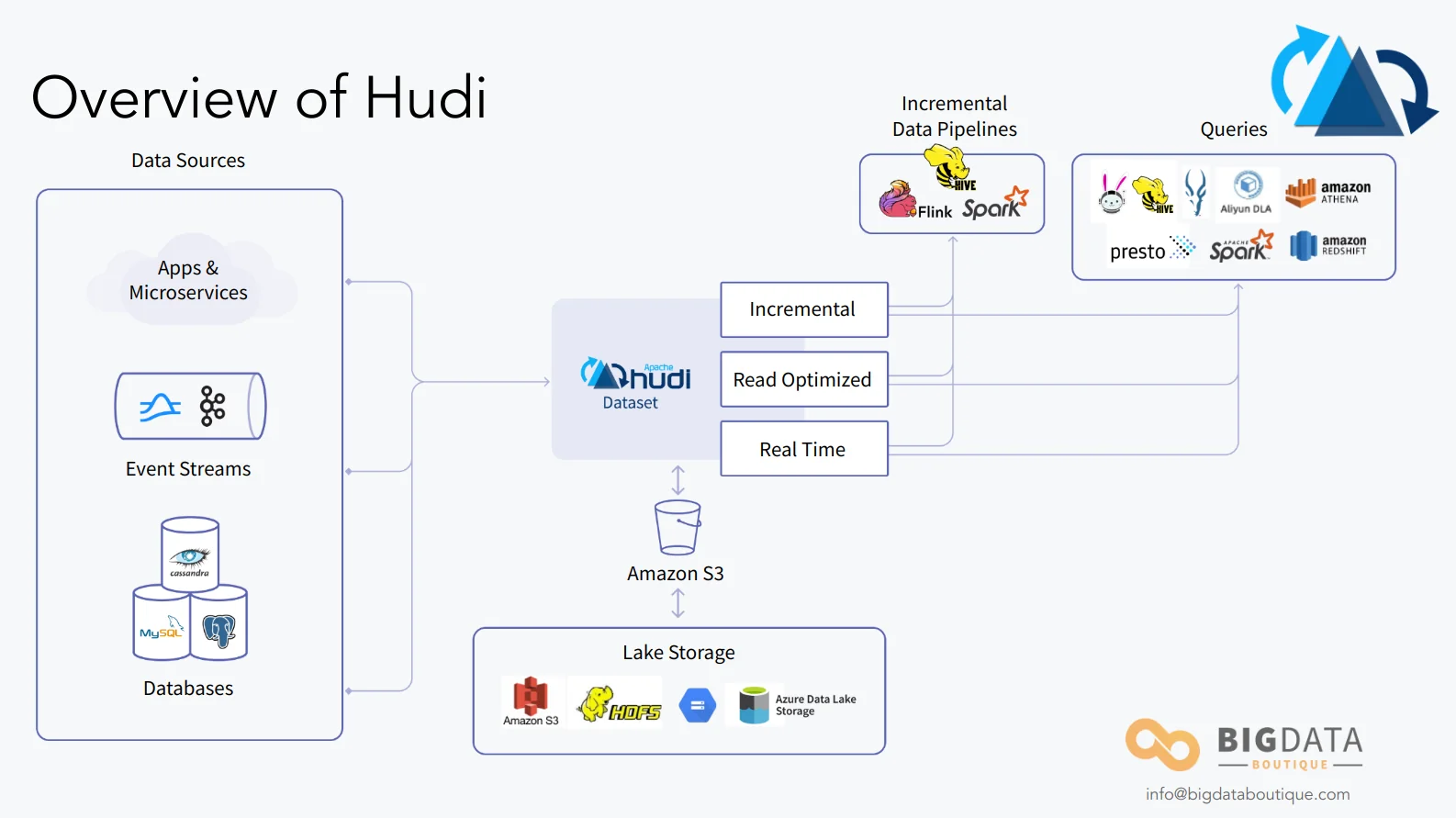
Updates and Deletes
A modern data platform must provide robust support for updates and deletes even when data resides on cheap object storage. Hudi has both.
Deletes
Hudi supports two types of deletes for compliance and privacy requirements.
Soft deletes retain the record but set the data values to null. Provided the target fields are nullable in the schema, this works well for standard deletes not related to privacy or compliance. Soft deletes can be rolled back using the retained record.
Hard deletes permanently erase all trace of a record from the table. There are three ways to do this: using DataSource with OPERATION_OPT_KEY, using DataSource with PAYLOAD_CLASS_OPT_KEY, or using HoodieStreamer with a delete column indicator.
Updates
Hudi offers two update strategies that behave very differently.
Insert is a fast operation that can tolerate multiple duplicates in a table. There is also a BULK_INSERT operation, a scalable variant capable of handling hundreds of terabytes.
Upsert is the default in Hudi. It performs an index lookup before writing, which makes it slower than insert but prevents duplicates and optimizes file sizing.
Partial Updates (Hudi 1.x)
Hudi 1.x introduced partial updates, allowing you to update specific columns in a record without rewriting the entire row. This is particularly useful for wide tables where different pipelines own different columns - each pipeline can update its columns independently without overwriting values set by other pipelines.
Hudi's Table Format
To support these features, Hudi uses a partitioned directory structure similar to traditional Hive tables but introduces a commit log called the "timeline" which tracks all operations performed on a table.
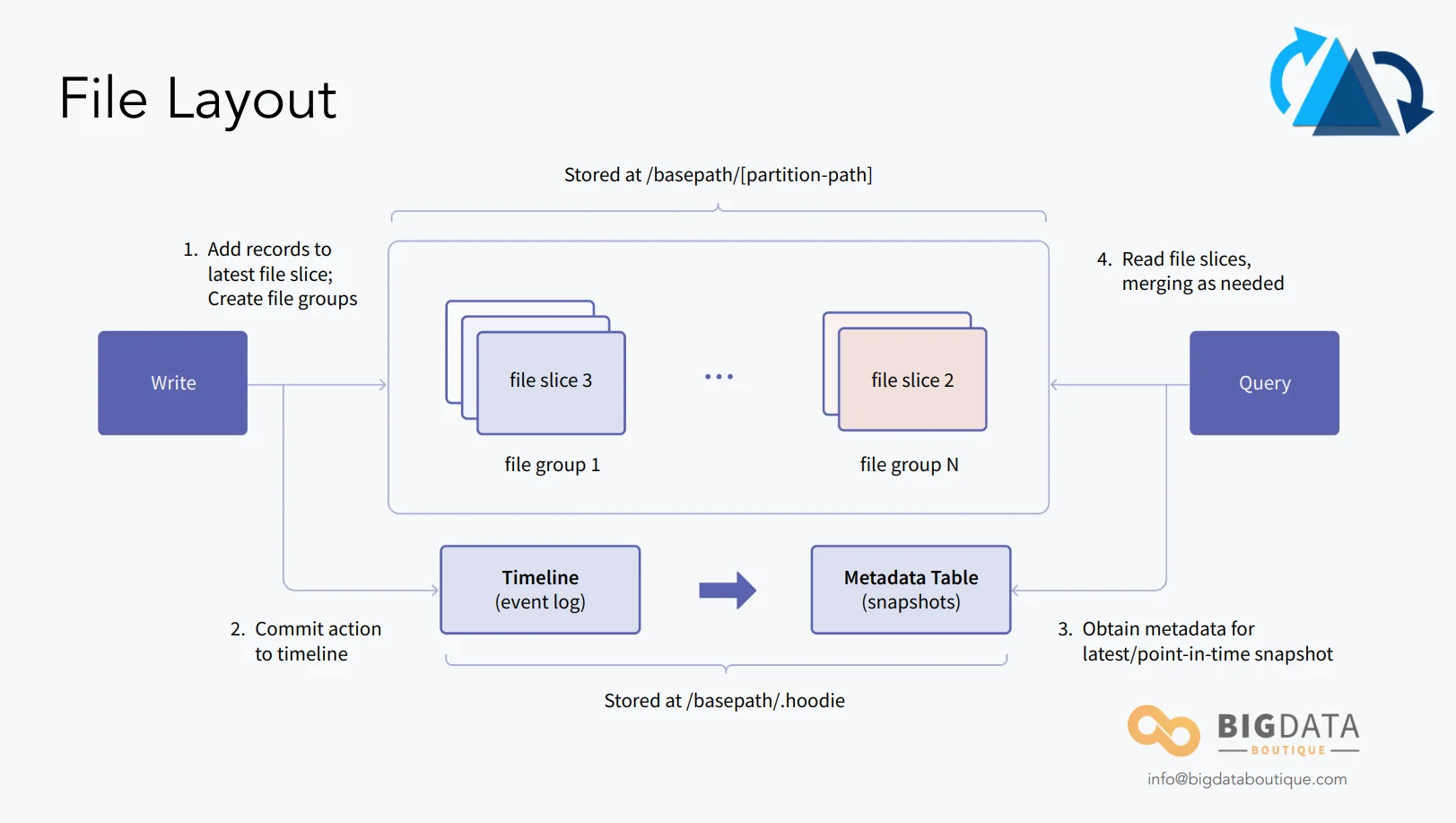
In Hudi 1.x, the timeline was re-architected to use an LSM (Log-Structured Merge) tree-based design. This replaces the previous approach of storing individual timeline files in HDFS/S3, which caused performance issues at scale due to the large number of small files. The LSM-based timeline compacts metadata into fewer, larger files and improves timeline operation performance significantly for tables with thousands of commits.
The table format and how data is written are rigorously explained in the Hudi docs: file layout, writing path. What's more relevant here is how this data is queried and the different query types Hudi offers.
Apache Hudi Query Types
Copy on Write and Merge on Read are two different approaches to handling updates in data storage. With Hudi, you choose between Copy on Write (CoW) or Merge on Read (MoR) on a per-table basis to optimize for either reads or writes.
Copy on Write
Copy on Write creates a new version of the affected data files every time an update or delete is requested. The original data remains intact for concurrent readers, and the updated data is written to a new copy. Old copies are eventually cleaned up.
CoW is best for read-intensive workloads with a lower rate of change. Hudi defaults to CoW. Every update or delete produces a new version of the modified files during the write operation.
Merge on Read
Merge on Read stores updates separately in delta log files rather than rewriting base files immediately. The deltas are merged with the base data at read time.
MoR is best for write-heavy data or high change rates. It uses a mix of Parquet (base files) and Avro (log files). Hudi creates two views in Hive - a read-optimized view (base files only, faster but potentially stale) and a real-time view (base + delta logs, always current).
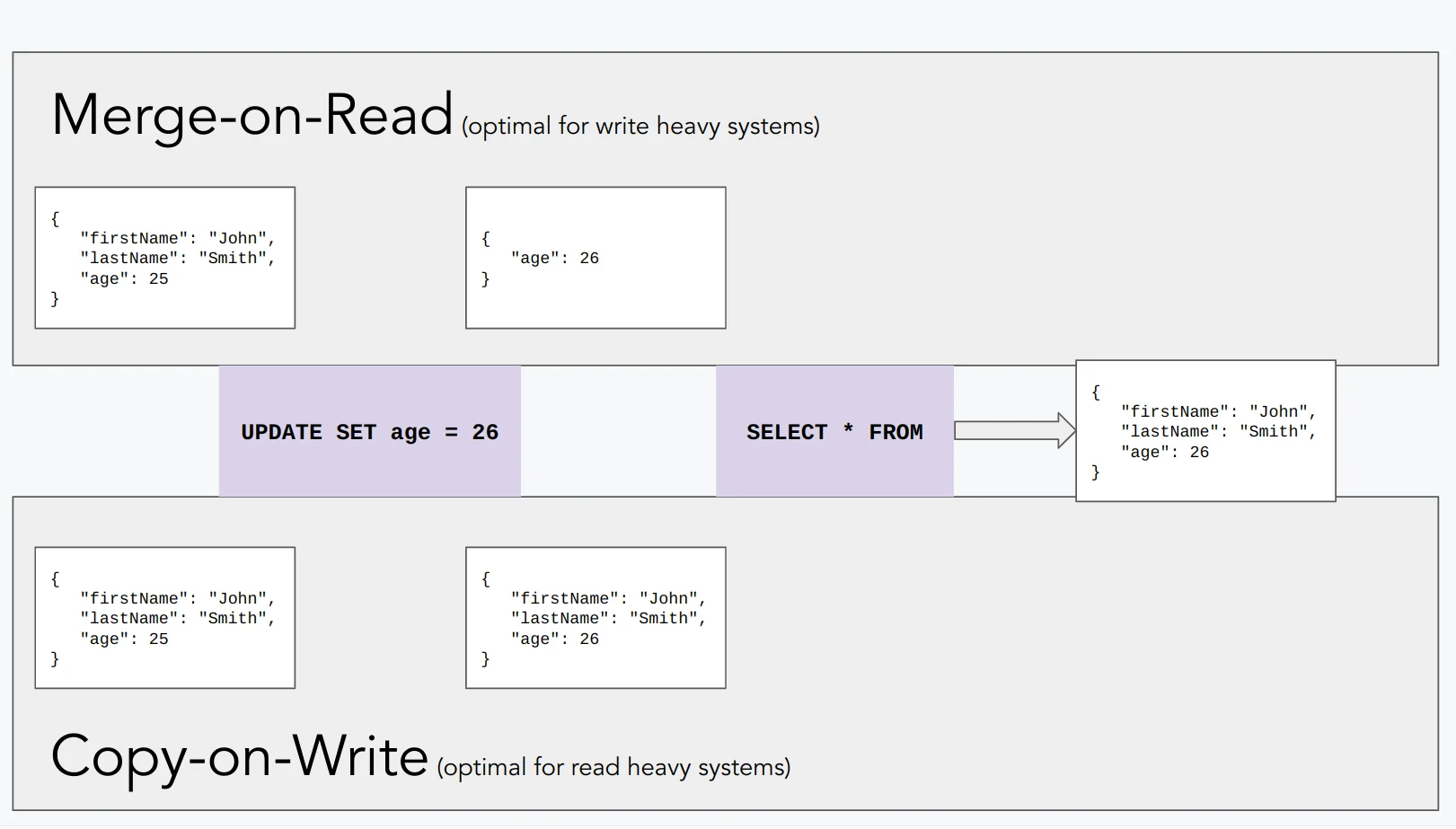
The trade-off is direct: MoR delivers higher write throughput at the cost of slower reads (since deltas must be merged). CoW has slower writes but faster queries. The choice depends on your workload's read-to-write ratio.
Indexing and Query Performance
Hudi uses record-level indexes to locate which file groups contain specific records, which is essential for efficient upsert and delete operations. Hudi 1.x introduced a multi-modal indexing subsystem that goes beyond the original bloom filter and simple indexes:
- Record-level index: Maps each record key to its file group, enabling O(1) lookups for upserts instead of scanning all file groups.
- Secondary indexes: Allow indexing on non-primary-key columns, useful for queries that filter on fields other than the record key.
- Functional/expression indexes: Support indexes on derived expressions (e.g.,
date_format(ts, 'yyyy-MM-dd')), enabling efficient partition pruning without changing the physical partition layout. - Bloom filters: The original indexing mechanism, still useful for point lookups on large tables when a full record index would be too large.
These indexes are stored as Hudi metadata tables and are maintained transactionally alongside data writes.
Apache Hudi: A Stream-Based Approach
Hudi differentiates itself from other data lakehouse platforms with its own ingestion tool, HoodieStreamer (renamed from DeltaStreamer in Hudi 1.x). This enables Hudi to ingest data from a variety of sources with shared capabilities. A unique capability is managing data at an individual record level in object storage while HoodieStreamer handles the ingestion, making CDC and data streaming straightforward.
HoodieStreamer
HoodieStreamer sits separately from Hudi as a standalone utility. It ingests data from DFS, database change logs, and Kafka. It supports both one-off and continuous ingestion modes.
Run-once performs an incremental pull of events and ingests them into Hudi. For MoR tables, compaction is automatically enabled. Continuous mode creates an infinite loop of ingestion at a configurable frequency. If you enable continuous mode, allocate appropriate resources since compaction and ingestion run concurrently.
Object Store Access
Because Hudi manages data at the record level within object storage, it supports a range of storage backends: Azure Blob Storage, Google Cloud Storage, and AWS S3, with built-in consistency checking on S3. Query Hudi data using Hive, Spark, Trino, Presto, or Flink.
Apache Flink Support
Apache Flink provides a stream processing engine that returns queries in near real-time through continuous queries.
Flink Continuous Queries
The integration of Flink continuous queries with HoodieStreamer creates a strong capability for stream analysis during ingestion. It relies on Hudi's native CDC support in object storage - message changes in the data stream are retained and consumed, which Flink then analyzes in real-time, cutting latency in ETL pipelines significantly.
What Changed in Hudi 1.x
Hudi 1.x represents a major architectural evolution. Key changes include:
- Non-Blocking Concurrency Control (NBCC): Multiple writers can operate on the same table concurrently without blocking each other, using optimistic concurrency control with conflict detection at the file group level.
- LSM-based timeline: The commit timeline moved from individual files to an LSM tree structure, fixing the small-files problem that slowed metadata operations on long-running tables.
- Multi-modal indexing: Record-level, secondary, and functional indexes are now built into the platform as first-class features (see Indexing section above).
- Partial updates: Update specific columns without rewriting entire records - critical for wide tables with multiple write pipelines.
- Native Iceberg catalog support: Hudi 1.x can expose tables through the Iceberg catalog interface, allowing Iceberg-compatible query engines to read Hudi tables without Hudi-specific connectors.
- DeltaStreamer renamed to HoodieStreamer: Reflects the broadened scope of the tool beyond just "delta" ingestion.
Apache Hudi vs Apache Iceberg
Both Hudi and Apache Iceberg are open-source table formats for data lakehouses, but they prioritize different problems. Here's how they compare:
| Dimension | Apache Hudi | Apache Iceberg |
|---|---|---|
| Origin | Uber (2016), focused on CDC and streaming ingestion | Netflix (2017), focused on correctness and schema evolution |
| Record-level operations | Native upsert, delete, partial update | Merge-on-read via positional deletes (v2 format) |
| Streaming ingestion | HoodieStreamer with Kafka, DFS, CDC sources | Flink sink, Spark structured streaming |
| Concurrency control | NBCC (Hudi 1.x), optimistic file-group level | Optimistic concurrency with retry |
| Indexing | Multi-modal (record, secondary, functional, bloom) | Partition pruning, manifest-level min/max stats |
| Query engine support | Spark, Flink, Trino, Presto, Hive | Spark, Flink, Trino, Presto, Dremio, StarRocks |
| Schema evolution | Avro-based, schema-on-write | Full schema evolution (add, rename, reorder, drop columns) |
| Time travel | Supported via timeline | Supported via snapshot IDs |
| Adoption trend | Strong in CDC-heavy and streaming-first architectures | Broader adoption as default lakehouse format |
If your primary use case is streaming CDC ingestion with frequent record-level updates, Hudi's native upsert and HoodieStreamer tooling give it an edge. If you need broad query engine compatibility and prioritize schema evolution flexibility, Iceberg has stronger ecosystem momentum. For more on Iceberg, see our Iceberg architecture deep dive and our comparison of Iceberg vs Delta Lake.
Production Deployment Considerations
Running Hudi in production requires attention to several operational dimensions:
- File sizing: Target 128-256 MB base files for a balance between query performance and write amplification. Hudi's auto-sizing features help, but monitor actual file sizes in production.
- Compaction strategy: For MoR tables, compaction frequency directly affects read performance. Too infrequent compaction means reads must merge more delta logs. Too frequent compaction wastes compute. Start with the default strategy and tune based on your read/write ratio.
- Concurrency and clustering: With Hudi 1.x NBCC, multiple writers work concurrently, but you still need to plan clustering (physical data layout optimization) as a separate background process. Clustering reorganizes data files by sort key, improving query performance for common filter patterns.
- Indexing configuration: Choose the right index type for your table size and access pattern. Bloom filters work well for point lookups on large tables. Record-level indexes give the fastest upsert performance but require more storage. Secondary indexes add read flexibility at the cost of write overhead.
Key Takeaways
- Apache Hudi is a data lakehouse storage framework that enables record-level insert, update, and delete operations on cloud object stores, originally built at Uber for CDC ingestion at scale.
- Hudi supports two table types: Copy on Write (optimized for reads) and Merge on Read (optimized for writes), chosen per table based on workload patterns.
- Hudi 1.x introduced non-blocking concurrency control, LSM-based timeline, multi-modal indexing, and partial updates - a significant architectural upgrade.
- HoodieStreamer (formerly DeltaStreamer) provides built-in streaming ingestion from Kafka, DFS, and database change logs.
- For CDC-heavy and streaming-first data architectures, Hudi remains a strong choice. For broader ecosystem compatibility, consider Apache Iceberg as well.

