 Roi Tabach
Roi Tabach
This post explores how semantic search – powered by large multi-modal models and Amazon OpenSearch Service – can significantly enhance image retrieval accuracy and relevance.
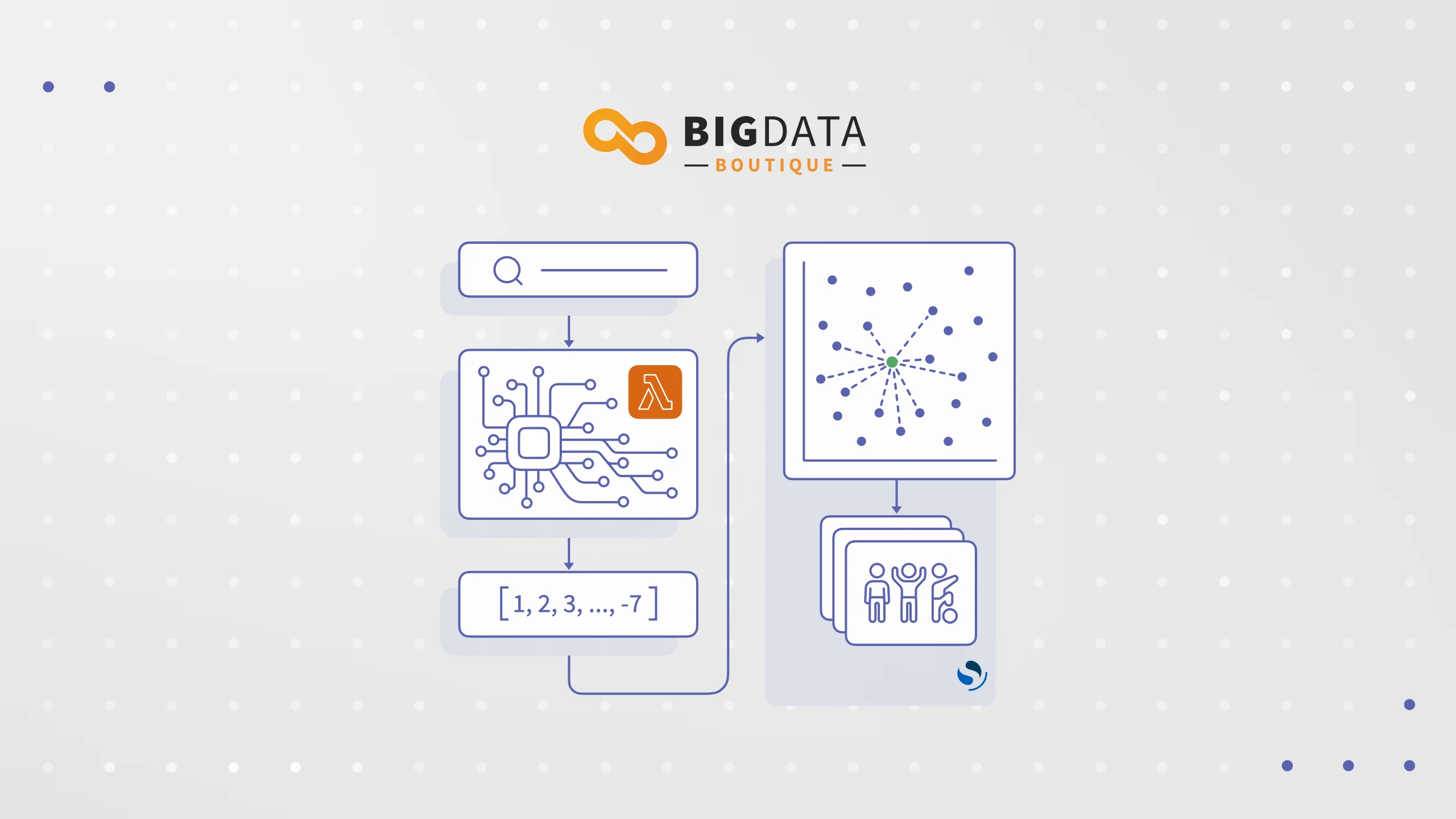
Introduction
When typing a query to a search engine, users often wish the search engines understood what they're looking for. In the world of image search, that means getting the most relevant results. However, the traditional "tag and keyword" approaches often fall short, missing the nuance in the user’s search intent.
Traditional image search methods struggle with precision and conceptual understanding. Images are at their core complex arrays of pixel data, and traditional search engines cannot interpret this raw information meaningfully, or intrinsically understand the visual content, concepts, or relationships within an image. This makes searching for images based on what they depict, rather than on their file names or basic metadata, exceptionally difficult.
Problem: Tag-based approaches to image search have many limitations
Image tagging provides a classic solution to the image search problem. Images are assigned descriptive labels, either manually by humans or using automated systems like Amazon Rekognition. You can add such tags to image data using crowdsourcing or ML-based methods. The tagged images are then stored in a searchable database like Amazon OpenSearch Service. When a user enters a search query, standard string operations (splitting and lemmatization) are applied, and the search engine looks for matching tags to retrieve relevant images.
However, this approach has its limitations due to its reliance on limited metadata and strict keyword matching. These lead to several shortcomings: inaccurate results (for example, a search for "red dress" returning images with any red elements) and the inability to handle nuanced searches based on actions or relationships within the image (for example, a search for "man looking at the phone").
In this approach, image ingestion would look like this:
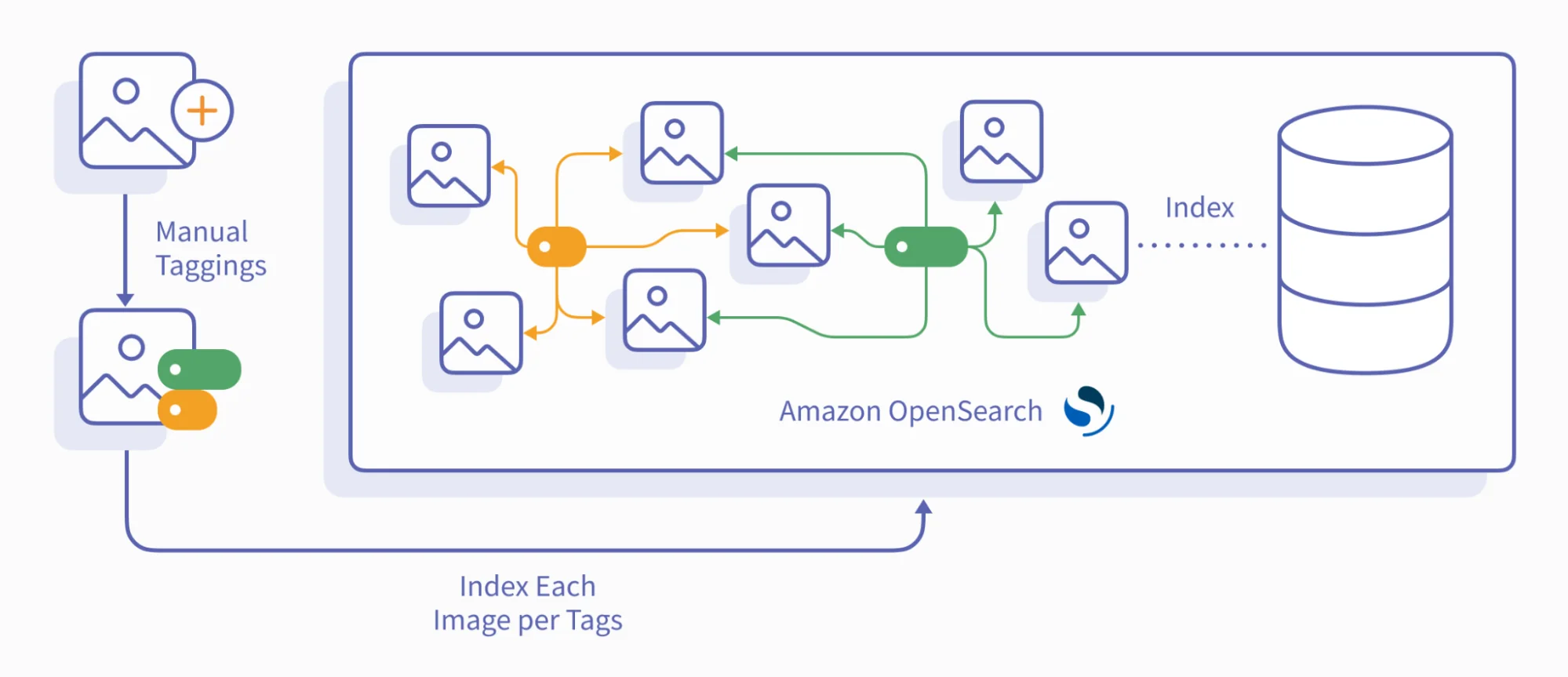
As seen above, each image is manually tagged using a close list of tags by the manual tagging team. Each image is then uploaded to the OpenSearch cluster and indexed per the tags.
The search pipeline would look like this:
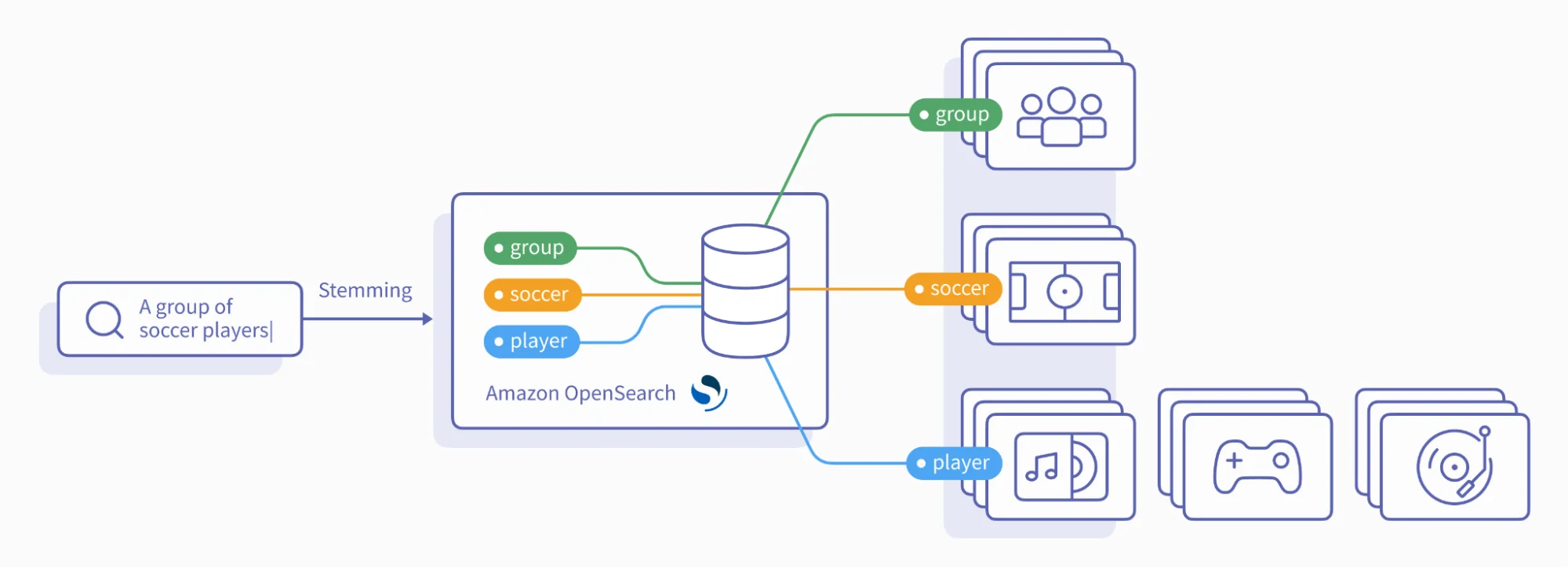
When a user searches for a phrase, it’s passed through stemming and then retrieved from OpenSearch based on the tags. The results from each tag can be combined through an intersection or union.
Solution overview
While traditional tag-based image search is useful, it comes with several limitations:
- Tag dependency – Search results are constrained by the existing tag vocabulary, and mismatches may lead to omissions.
- Manual tagging is resource-intensive – Manual tagging requires a lot of time and effort.
- Keeping up with evolving user search patterns is challenging – Users will always find new ways to search, outpacing the tags our team can provide. Yet, without a pool of possible tags, we risk inconsistent labeling of similar images.
To eliminate these shortcomings and improve retrieval relevance, we may turn to multimodal models and vector search.
OpenAI's CLIP, launched in 2021, is an example of a solution that creates image and text embeddings that live within the same semantic space. Trained on vast image-text pairs, CLIP grasps the connections between visual content and its textual description.
The model takes images and texts and transfers them to vectors in a way that preserves semantic relations: Semantically close words are near each other in the vector space. Images are close to phrases that describe them (or parts of them).
For example, “an image of a dog” and an actual image of a dog are closer (in the cosine distance of the embedding vectors) than “an image of a dog” and an image of a mountain. This technique is called contrastive learning, and while CLIP isn't the first model to use it, it was the first model to take contrastive learning this far.
Implementing semantic image search with Amazon OpenSearch Service and CLIP
To power our semantic image search, we carefully prepare images and utilize OpenSearch's vector search capabilities. Here's a step-by-step approach:
1. Image embedding
We process raw images using the CLIP model, generating vector representations. To ensure compatibility with CLIP, images are cropped to a square aspect ratio and resized to 240x240 pixels.
2. Vector indexing
Embeddings are stored in an OpenSearch vector index for efficient search. This process is implemented both during the ingestion of new images and as a one-time pass on all existing images within our platform.
3. Query embedding
When a user searches for an image, the query is also embedded using the CLIP model.
4. Nearest neighbor search
The search engine retrieves the top 30 most similar image embeddings (nearest neighbors) in the vector index, ensuring more relevant search results for our users.
Solution result
Image ingestion would now look like this:
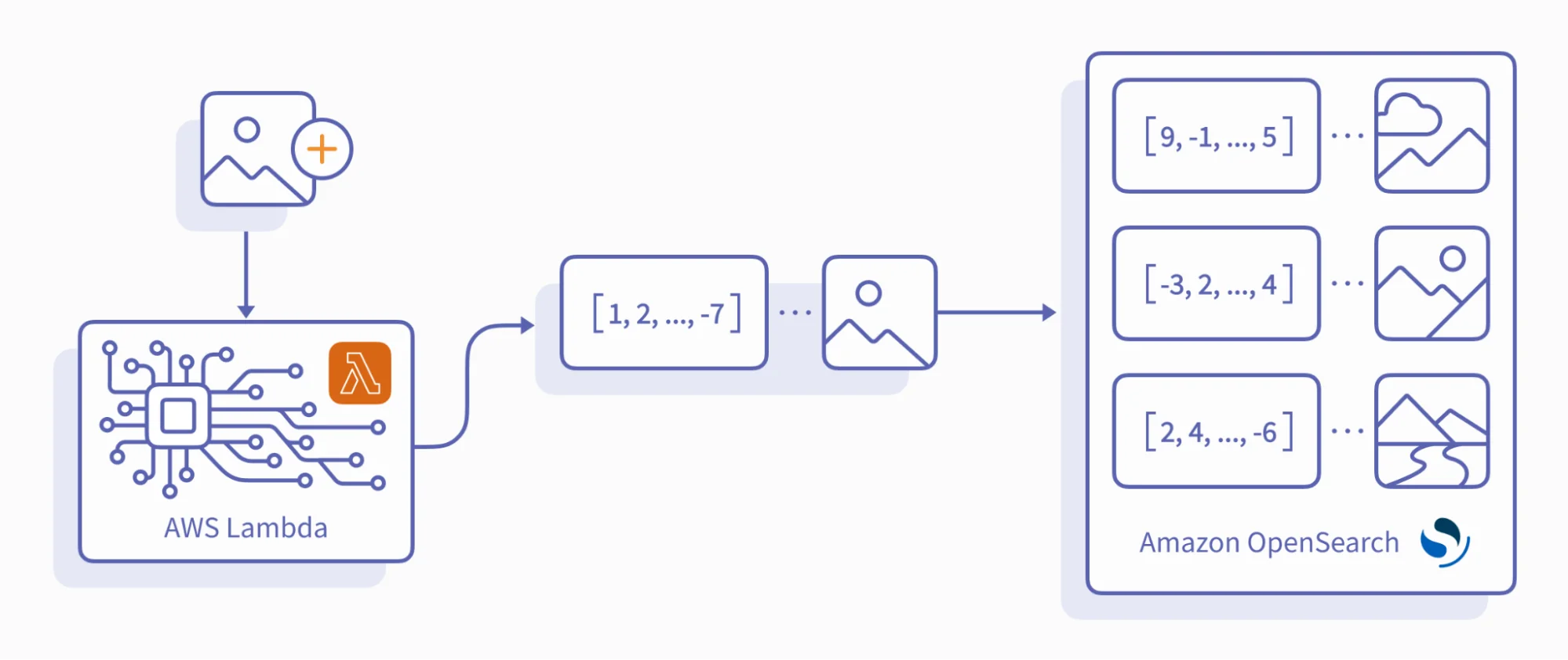
Upon image ingestion, CLIP embeds each image into a vector. The system then uploads both the image and its corresponding vector to the OpenSearch cluster's vector index.
The search pipeline would look like this:
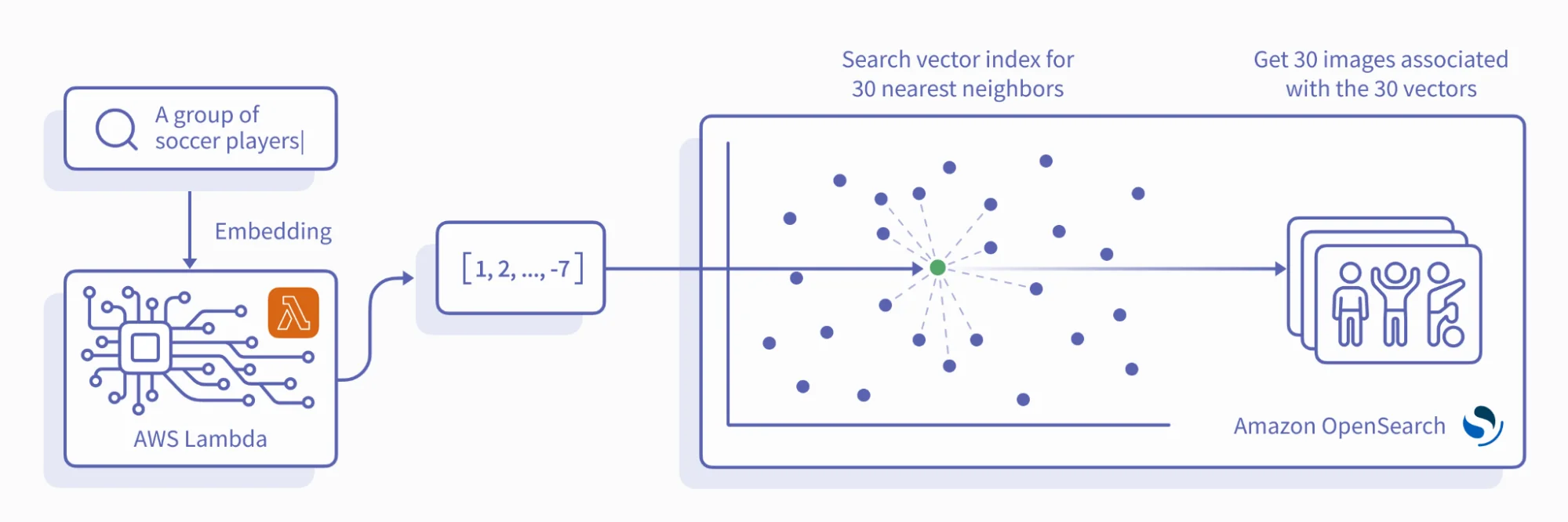
CLIP embeds a user's search term as a vector. This vector queries the OpenSearch vector index for the 30 nearest neighbors, and their associated images are retrieved.
Note:
- CLIP can associate images with related concepts even if they aren't tagged. For example, an image with a football field in the background might still be retrieved for the search term 'sports.'
- CLIP’s early training means prompt engineering is crucial for optimal results. While it excels at embedding sentences and descriptions of actions, single-word terms often perform better when placed inside templates like "a picture of a {{term}}".
Summary
By integrating CLIP and OpenSearch, we can build a powerful semantic image search solution. This approach delivers a more intuitive and accurate user experience, surpassing the limitations of traditional keyword-based methods.
To learn more about our OpenSearch consulting services and how we can assist you with your next project, click HERE.

