 Roi Tabach
Roi Tabach
In today’s competitive digital marketplace, delivering a great search experience is key. This blog shares how we used Amazon OpenSearch and Amazon Bedrock to enhance a customer’s search functionality, including using a large language model (LLM) to improve synonym expansion.

Introduction
In the competitive world of digital marketplaces, delivering a seamless search experience is vital for success. However, effectively handling synonyms and understanding user intent remains a persistent challenge. In this blog, I'll share the key insights and learnings my team and I at BigData Boutique gained by integrating Amazon OpenSearch and Amazon Bedrock to transform a customer's search functionality. This isn't meant to be a detailed case study, but rather a practical guide to equip you with actionable steps and considerations as you build your own approach to search optimization. I'll also detail our real-world approach to synonym expansion, powered by a large language model (LLM), to boost search performance significantly.
The Challenge: Synonym Deficiency and Semantic Gap
Search engines have a blind spot when it comes to synonyms. A search for "Sport" might completely miss results tagged as "Soccer." This gets even more frustrating with context-dependent words like "orange" – are we looking for the fruit, the color, or a mobile network? This common limitation reveals the urgent need for smarter, more comprehensive semantic search solutions that can understand the relationships between words, ensuring that searches are both accurate and intuitive.
Our Approach: Leveraging LLMs and Amazon Bedrock
Amazon Bedrock simplifies integrating and managing advanced language models (LMs) for various use cases. Along with streamlined access, Amazon Bedrock emphasizes privacy and compliance – ensuring your data remains private and doesn't contribute to general model training. In our quest to revolutionize search, we leveraged Amazon Bedrock to integrate a powerful LLM. This model served as a highly insightful product analyst for us, constantly analyzing and providing feedback to refine our search results where more common and traditional approaches failed.
First, we integrated Amazon OpenSearch, laying the foundation for a robust search infrastructure. Then, we utilized Amazon Bedrock to introduce the LLM as our virtual analyst. This combined approach allowed us to “re-invent” a well-established search improvement technique called Synonym Expansion. This technique significantly boosted the accuracy of our search results, ensuring a more comprehensive and intuitive user experience.
Here's a breakdown of how we landed with this solution step-by-step:
Approach 1: Naive Synonym Expansion and Using WordNet
When starting a project that includes complicated machine learning (ML), we always begin with the simplest baseline. In our case, we began with a WordNet-inspired synonym to expand search terms. The approach improves upon manually creating huge ontologies but still has some limitations around context. For instance, searching for "sport" might surface "exercise" as a synonym – misaligned with someone looking for soccer or football gear.
If you’re building a similar model and broad English synonyms are sufficient, consider using SynonymFilter. It provides a straightforward approach to improve search results without the need for complex configurations or custom tools, making it ideal for various use cases.
Approach 2: Semantic Search
In recent years, machine learning and natural language processing (NLP) advancements have offered a powerful search refinement alternative: embeddings. Embedding models transform words (or images) into vectors, allowing for similarity-based searches via tools like Amazon OpenSearch's Vector Index feature. For a deeper dive into this approach, see our blog post, “Implementing Semantic Image Search with Amazon OpenSearch.”
In this approach, we feed the customer's entire search query directly into a powerful language model (like Amazon Titan Embeddings. These language models are specially trained to turn queries into vectors, placing them in a virtual space where similar concepts are close together. Even long, detailed searches like "shoes you can wear for a festive dinner" get matched to relevant products like “high heels,” even if the exact search term isn't used. The result? More accurate search results that help customers find what they truly need.
The embedding model can be deployed using AWS (as a standalone AWS Lambda function or Amazon SageMaker Jumpstart and then queried whenever a user performs a search.
While versatile, embedding models struggle with traditional keyword-based searches. For example, a word like "dinner" appears frequently and has broad associations, meaning its vector embedding sits near many unrelated terms. This "similarity to everything" issue blurs results, particularly when a user's search is short and keyword-focused. For these use cases, we found that semantic search alone produced unacceptable outcomes. To address these cases, we adopted a third approach.
Approach 3: Query-Time Synonym Expansion Utilizing Amazon Bedrock
Here, we move beyond traditional embedding techniques, instead harnessing the LLM's ability to process long contexts and generate its own examples. Despite consulting with the customer's product team, fully grasping user expectations remained elusive. This left us uncertain how to best address nuanced aspects of user intent via search term expansion.
That's when the breakthrough occurred—we uncovered the potential to leverage an LLM for "Context-Aware Synonym Expansion." Let's recreate one of our "aha!" moments – take a look at this Amazon Bedrock Playground screenshot (purple text denotes the model's insightful suggestions):
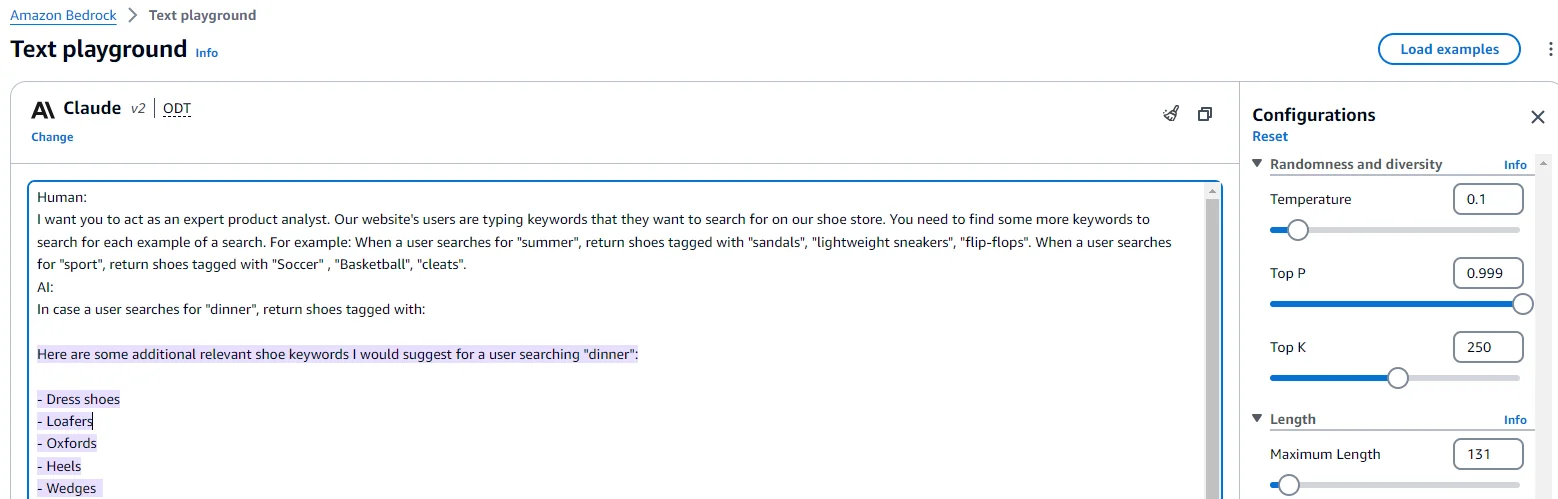
In Figure 1, we can see the end user is searching for “Dinner,” which can be expanded to include many different results depending on the context. Using our "shoe store" example, providing the LLM with relevant terms can generate more accurate synonyms for our specific domain.
Approach 4: Neural Sparse Retrieval
While we opted for context-aware synonym expansion using LLMs, another promising approach is Neural Sparse Retrieval. This method uses sparse representations to capture semantic nuances that dense embeddings might miss, effectively bridging the semantic gap. Neural Sparse Retrieval in Amazon OpenSearch Service operates in two modes: bi-encoder and document-only. In bi-encoder mode, both documents and search queries pass through deep encoders. In document-only mode, only documents are deeply encoded, while search queries are tokenized. This method can enhance short, keyword-focused searches, reduce costs, improve relevance, and lower latency.
Choosing the right LLM for the job
Before deploying our solution, we wanted to choose the best LLM for the task. To do this, we implemented a simple plan: compare a few LLMs on our handful of examples (our “golden set”) and see which performs best.
The world of measurements for LLM performance is vast, and we won’t dive deep into it in this blog post. Two things are worth considering:
First, some models performed so poorly that a simple test—whether they could generate new examples instead of just repeating examples from the prompt—was enough to eliminate them. This saved us from diving into complex semantic comparisons or perplexity measures.
Second, the LLM landscape is constantly evolving. Thus, any comparison process needs to be automated and easily repeatable. For example, between working with the customer and writing this blog post, several new LLMs emerged (like Mixtral, Gemini, and Claude 3), offering better performance. Additionally, the terms of service for one LLM were changed in a way that could affect our ability to use the model in production.
We compared Antropic's Claude v1/v2, Cohere's command, and Meta's Llama v2 for context-aware synonym expansion. Claude v2 emerged as the winner for this specific task. Using Amazon Bedrock streamlined the process, giving us quick access to these models saving us significant time and resources.
Subsequently, we seamlessly integrated Claude into our production pipeline, capitalizing on the comprehensive examples provided in the Amazon Bedrock GitHub repository.
In this architecture, the keyword search process works like this:
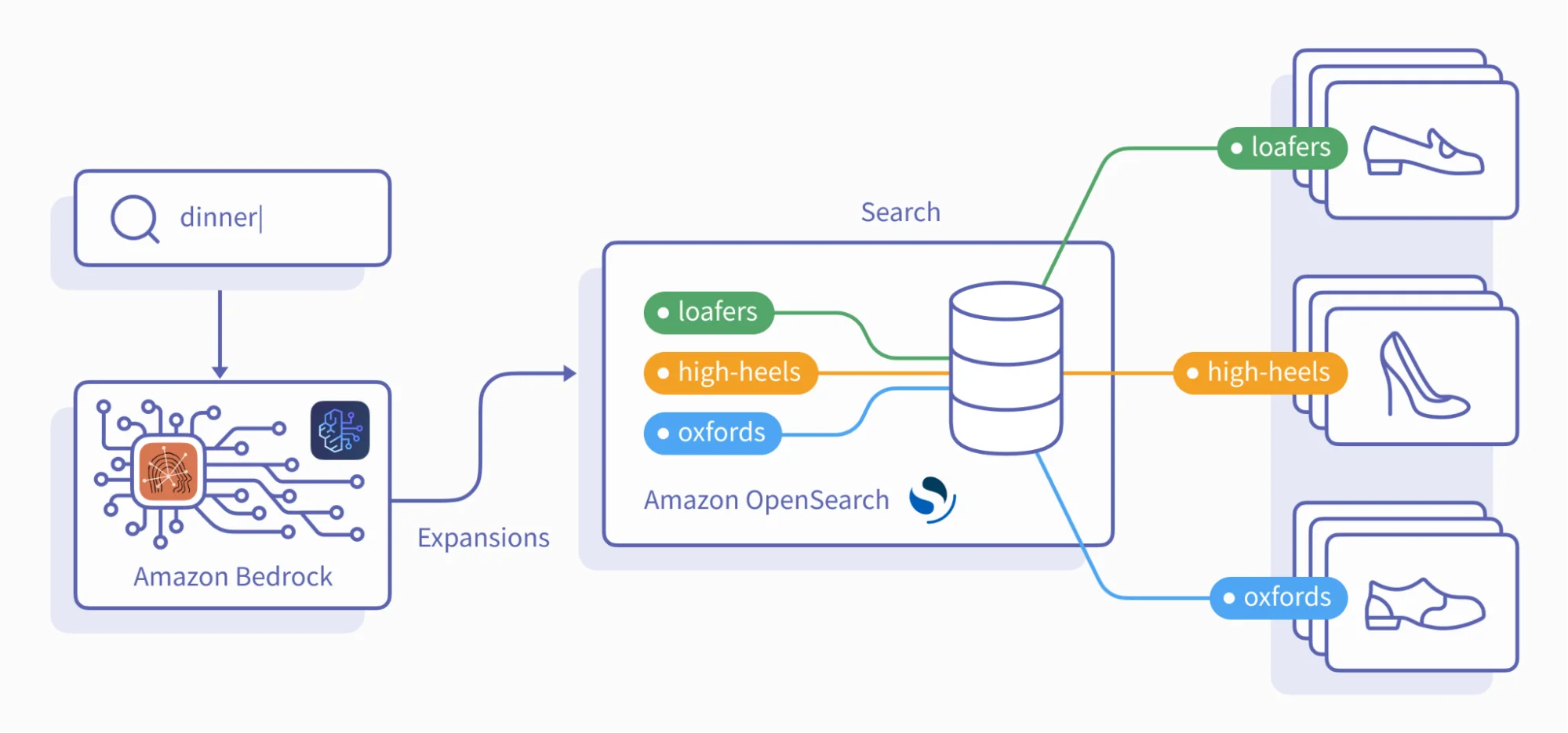
Figure 2 shows how a user's search keyword is sent to Claude on Amazon Bedrock for expansion. These expansions are then used to search in the Amazon OpenSearch cluster.
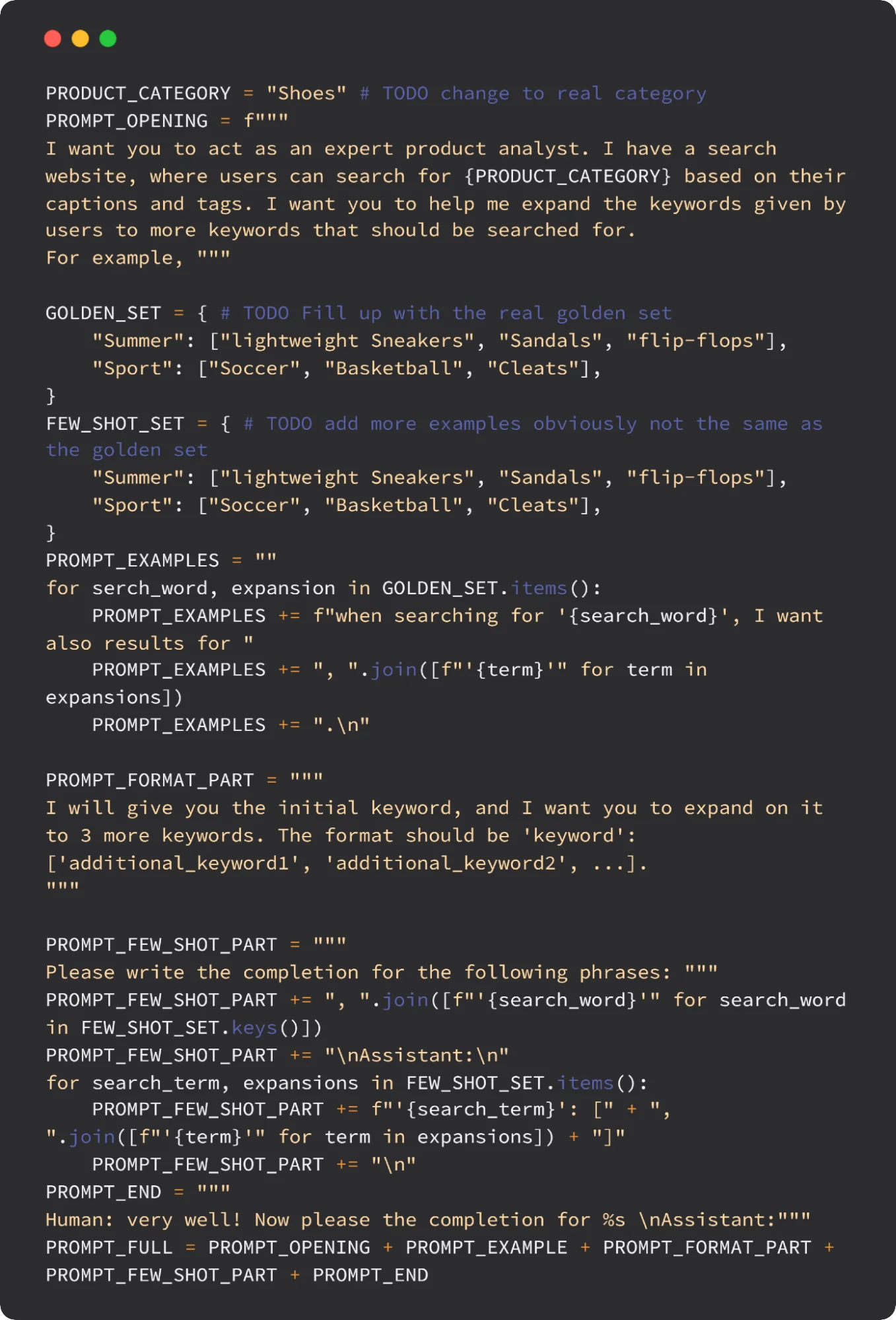
The Full Prompt:
Conclusion
We gained valuable insights throughout our journey by strategically utilizing Amazon Bedrock. These discoveries allowed us to empower our customer to leverage LLMs to re-invent a well-known concept like synonym expansion, ensure contextual awareness, and deliver an unparalleled search experience tailored to their users' needs.
To learn more about our OpenSearch consulting services and how we can assist you with your next project, click HERE.

