 Liza Katz
Liza Katz
In a recent webinar we showed how to build production-ready RAG applications with OpenSearch. Complete guide covering data processing, hybrid search, and LLM integration for AI chatbots and context-aware systems.

Retrieval-Augmented Generation (RAG) has rapidly become the go-to architecture for building powerful, accurate, and context-aware AI applications. By grounding Large Language Models (LLMs) with your own private data, RAG systems can answer questions, power chatbots, and automate tasks with information that goes far beyond the model's original training data.
In a recent webinar, Liza, a GenAI Team Lead at BigData Boutique, provided a crash course on the end-to-end process of building a production-ready RAG application with OpenSearch. This blog summarizes the key stages, practical techniques, and critical considerations she shared.
First, What is a RAG Application?
Before diving into the "how," it's essential to understand the "what." An LLM application uses a model via an API to create a unique user experience. While there are several patterns, RAG is specifically designed to augment an LLM's capabilities.
Here's how RAG fits into the landscape of LLM applications:
- Workflows: A series of tasks where an LLM is one step, perhaps to summarize a report or analyze customer sentiment from reviews.
- Chatbots: A conversational interface that interacts directly with an LLM, often guided by a specific prompt.
- RAG (Retrieval-Augmented Generation): The core of our discussion. This pattern involves:
- Storing your proprietary data in a database (like OpenSearch).
- Retrieving relevant information from that database based on a user's query.
- Using that retrieved information to "enrich" the context provided to the LLM, enabling it to generate a grounded, accurate answer.
- Agents: An advanced pattern where an LLM is given access to "tools" (which can include databases, APIs, or file systems) to perform complex, multi-step tasks.
Why Choose RAG?
LLMs are powerful, but they have limitations. RAG is the solution when:
- Your data is recent: LLMs are trained on a fixed dataset with a knowledge cutoff date. RAG provides access to real-time information.
- Your data is private or proprietary: You can't fine-tune a public model on sensitive user data. RAG allows the model to access this information securely at query time without retaining it.
- You need domain-specific knowledge: For industries with unique terminology (like insurance or finance), RAG provides the necessary definitions and context.
Ultimately, building a RAG application is an exercise in Context Engineering: the art of providing the LLM with focused, clear, and relevant information to help it perform its task perfectly.
The 3-Stage RAG Pipeline: An Overview
To illustrate the process, the webinar used a practical example: an insurance company wanting to build a chatbot that allows customers to "talk to their insurance policies" to ask about coverage, find doctors, and understand their benefits.
This use case maps directly to a three-stage RAG architecture:
- Document Processing & Ingestion: Raw documents (policies, provider lists, etc.) are processed, chunked, converted into semantic vectors (embeddings), and stored in OpenSearch.
- Query Processing & Retrieval: A user asks a question. The system processes the query, searches OpenSearch for the most relevant data chunks, and retrieves them.
- Generation & Response: The retrieved data is formatted and combined with the original query into a detailed prompt, which is sent to an LLM to generate a final, human-readable answer.
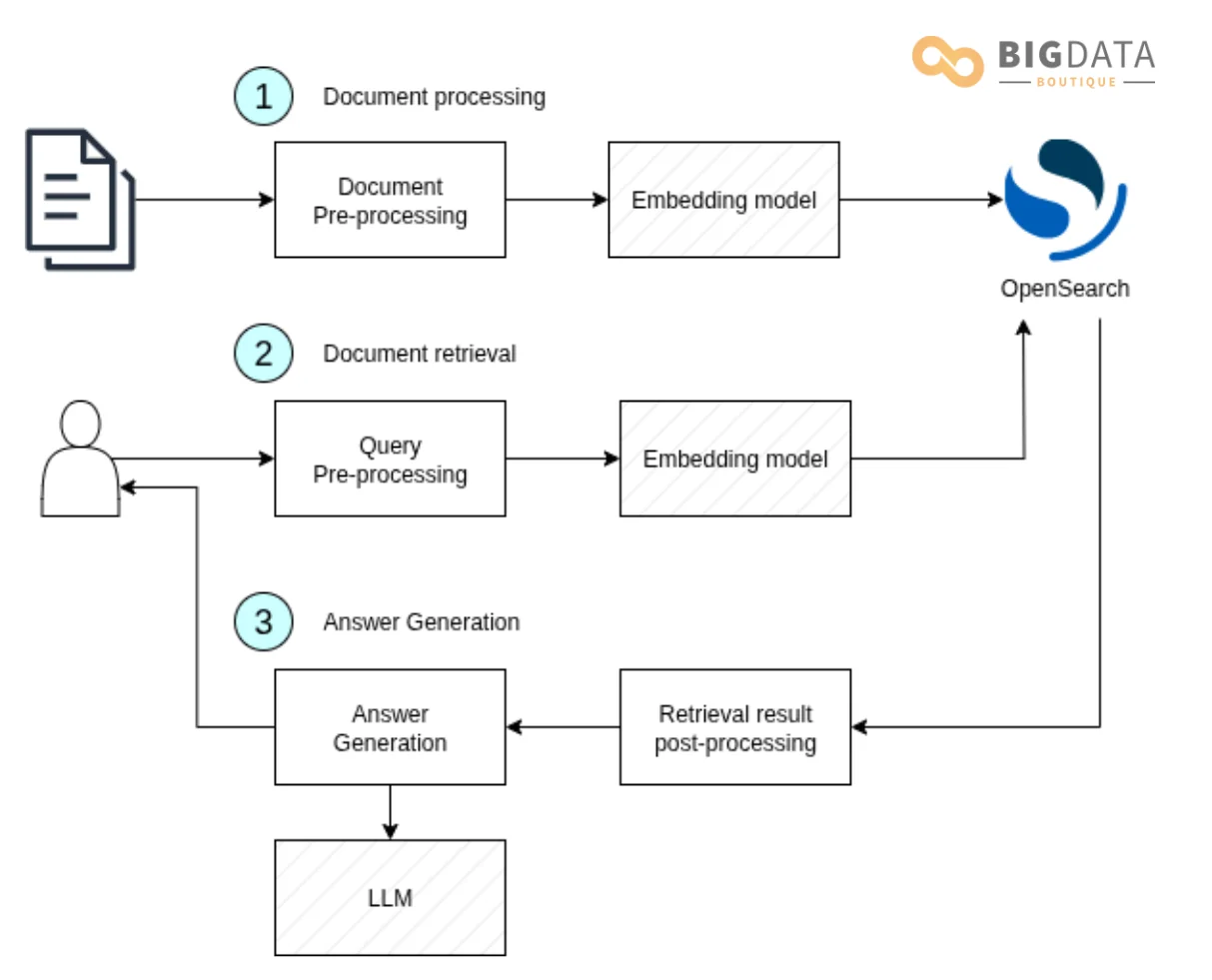
Stage 1 Deep Dive: Processing and Ingesting Your Data
Garbage in, garbage out. The quality of your RAG application depends entirely on the quality of the data you feed it.
The Most Important Step: Data Exploration
Before writing a single line of code, you must deeply understand your data. This is a collaborative process, often involving domain experts, to answer key questions:
- Inventory: What documents do you have? (e.g., PDFs, Word docs, database entries, PowerPoints).
- Relevance: What information is irrelevant and should be removed? (e.g., cover pages, boilerplate legal text).
- Hierarchy: Do your documents have a structure? (e.g., a policy with sections, subsections, and paragraphs). This structure is critical context.
- Privacy: What sensitive information needs to be redacted or removed? (e.g., credit card numbers, bank accounts).
- Question Space: What questions can and should your system be able to answer with this data? This inventory will become your evaluation set later.
From Raw Document to Indexed Chunk
Once you've explored the data, the technical pre-processing begins:
- Cleaning & Chunking: Clean the extracted text and break it into meaningful, manageable chunks. A chunk should be large enough to contain context but small enough to be focused on a single topic. A single sentence is often too little; a full page is often too much.
- Enrichment & Shaping: Add metadata and context to each chunk. For the insurance policy, this means adding the section and subsection titles to every chunk derived from that section. The text is then shaped into a clean, readable format (like Markdown) that both humans and LLMs can easily parse.
- Embedding: This is where the magic happens. An embedding model (a separate model from your generative LLM) converts each text chunk into a numerical vector. This vector captures the semantic meaning of the text, allowing you to find similar concepts regardless of the exact wording used.
- Ingestion: Finally, use the OpenSearch
_bulkAPI to index each chunk, storing its text, metadata, and the newly generated vector.
Stage 2 Deep Dive: Retrieval with Hybrid Search
With your knowledge base indexed in OpenSearch, you're ready to handle user queries.
From "My knee hurts" to a Search Query
When a user asks, "My knee hurts, can I see a doctor?", your system can't just pass that text to a database. It needs to be processed:
- Query Pre-processing: Use a smaller, faster LLM to clean the user's input and extract structured information, such as their intent (find a doctor) and specifics (knee problem).
- Contextual Awareness: The system should also consider chat history. If the user's next message is, "But I moved to San Francisco," the system must understand this is a follow-up and incorporate the new location into the search.

The Power of Hybrid Search in OpenSearch
To find the best information, you need to combine two types of search:
- Keyword Search: Excellent for finding explicit terms like "doctor" or filtering by a location like "San Francisco."
- Semantic (Vector) Search: Uses the embeddings to find conceptually related information. It understands that "knee hurts" is related to "orthopedic doctor," even if the word "orthopedic" isn't in the query.
Hybrid Search combines the precision of keyword search with the conceptual understanding of semantic search. The final OpenSearch query finds documents that are:
- A doctor (keyword match).
- Within 10km of the user's location (geospatial filter).
- AND are semantically similar to "knee problems" (vector search).
This delivers highly relevant results that neither search method could achieve alone.
Stage 3 Deep Dive: Generating the Final Answer
You've retrieved the best documents - now it's time to generate a helpful response.
- Format the Context: Take the retrieved documents (e.g., profiles of top-rated orthopedic doctors) and format them into a clean, human-readable text block for the LLM. Use formatting like Markdown and even emojis (e.g., ⭐ for ratings) to make the information clear.
- Construct the Prompt: Assemble all the pieces: the user's original query, the formatted context from the retrieved documents, relevant details from the user's policy, and a system prompt that instructs the LLM on how to behave (e.g., "You are a helpful insurance assistant. Answer the user's question based only on the provided information.").
- Generate and Respond: Send this comprehensive prompt to the generative LLM and return its answer to the user.
Making It Production-Ready: Key Challenges and Solutions
A successful demo is one thing; a reliable production system is another. Here are critical factors to consider:
- Reliable Pipelines: Document processing must be robust, with good observability and retry mechanisms to handle failures.
- Storage Optimization: Vectors are large. Use techniques like quantization (reducing numerical precision) or efficient new embedding models to manage index size and cost. On AWS, you can also back the vector index with S3 Vectors for cost-efficient hybrid search when latency requirements are relaxed.
- LLM Failures: LLMs can fail, return malformed responses, or hallucinate. Your system must be defensive, with retries, validation, and clear disclaimers for the user.
- Monitoring & Evaluation: This is perhaps the most under-discussed but crucial aspect.
- Monitor Everything: Log failures, latency, token costs (to avoid surprise bills), and, most importantly, user feedback (thumbs up/down).
- Evaluate Continuously: Use the "question space" you defined during data exploration to create a "golden set" of test questions. Run these tests regularly to catch regressions and ensure answer quality remains high.
- Pro Tip: Evaluate your retrieval step separately. It's much easier to measure whether you retrieved the right documents than to judge the quality of a generated paragraph.
Conclusion
Building a production-grade RAG application is more than just connecting an LLM to a database. It's a systematic process that hinges on deep data understanding, a sophisticated hybrid retrieval strategy, and a relentless focus on monitoring and evaluation. By following these stages and embracing the principles of context engineering, you can leverage OpenSearch to build powerful, reliable, and truly helpful AI solutions.
Based on the our recent webinar: "RAG with OpenSearch: A Crash Course for Building RAG Applications"
Ready to build your RAG system but need expert guidance? Our OpenSearch consulting team has helped enterprises implement production-ready RAG applications with OpenSearch, from data pipeline design to hybrid retrieval tuning.

