Itamar Syn-Hershko
Itamar Syn-Hershko
This Weekly Chunk is your GenAI Engineering digest. This week: About Software 3.0, LLM text filters, Transformers visualized, advanced RAG, & Airbnb's EBR.

Ever feel like the ground beneath our digital feet is shifting faster than ever? It’s clear that Large Language Models are a primary seismic force, moving beyond abstract potential into concrete, paradigm-altering applications. We're witnessing a pivotal moment where the very fabric of software development, information retrieval, and even how we conceptualize computing is being rewoven. From Andrej Karpathy’s provocative vision of "Software 3.0" – where English itself becomes a programming language – to tangible business impacts like Airbnb’s booking surge driven by smarter search, the transformation is undeniable and accelerating, touching everything from developer workflows to consumer experiences.
This week's The Chunk is your compass for navigating these critical developments. We're dissecting Karpathy's insights on our LLM-driven future and the intriguing concept of AI as "people spirits." We'll then explore the practical magic of LLMs dynamically structuring raw text for instant, intuitive search filters, and take a visual journey into the core 'attention' mechanisms that make Transformers so powerful - and finally easy to understand.
Furthermore, you’ll discover advanced RAG techniques essential for building more reliable AI systems and learn from Airbnb's real-world success with embedding-based retrieval. Prepare to gain not just an overview, but a deeper understanding of the mechanics, challenges, and immense opportunities unfolding right now, equipping you to stay ahead in this rapidly evolving landscape.
Let's start.

Andrej Karpathy outlines a fundamental shift in software development with the advent of "Software 3.0," where Large Language Models (LLMs) are programmed in English, becoming a new type of computer. He likens LLMs to utilities, fabs, and most accurately, new operating systems, currently in an early, "1960s-like" era of centralized, time-shared computing. This paradigm shift means developers must become fluent in Software 1.0 (traditional code), 2.0 (neural network weights), and 3.0 (English prompts for LLMs). Karpathy emphasizes that this technology is uniquely diffusing to consumers first, empowering individuals to program these new "computers."
Karpathy describes LLMs as "people spirits"—stochastic simulations of people with encyclopedic knowledge but also cognitive deficits like hallucinations and jagged intelligence. This necessitates building "partially autonomous" applications, like Cursor or Perplexity, which feature human-in-the-loop verification, GUIs for rapid auditing, and "autonomy sliders." He stresses augmenting human capabilities ("Iron Man suits") over fully autonomous agents initially. Finally, he advocates for creating "agent-ready" digital infrastructure, with LLM-friendly documentation and interfaces (e.g., `lm.txt`, Markdown docs with machine-executable commands), to enable seamless interaction for this new class of digital information consumers.

This article details advanced Retrieval Augmented Generation (RAG) techniques, enhancing the standard "Search + LLM prompting" approach by effectively grounding Large Language Models (LLMs) in external data. Moving beyond naive RAG, it outlines key improvements such as optimized data chunking and vectorization, alongside sophisticated search indexing methods like hierarchical indices and Hypothetical Document Embeddings (HyDE). Crucial strategies include context enrichment—"retrieve smaller chunks for better search quality, but add up surrounding context for LLM to reason upon"—achieved via Sentence Window or Auto-merging Retrievers. Fusion retrieval, combining keyword and vector search, boosts accuracy, while reranking and filtering further refine context. An initial actionable takeaway highlights that "Prompt engineering is the cheapest thing you can try to improve your RAG pipeline."
More sophisticated techniques involve LLM-driven query transformations (decomposition, step-back, rewriting), robust chat engines for maintaining conversational context, and intelligent query routing. Agentic RAG architectures enable complex tasks like multi-document analysis but face latency challenges. The article also covers various response synthesis strategies and the benefits of model fine-tuning for both encoders (citing a 2% retrieval uplift) and LLMs (a 5% faithfulness increase with distillation; RA-DIT showing ~5% gains on knowledge-intensive tasks). Comprehensive evaluation using frameworks like Ragas or TruLens, focusing on the "RAG triad" (context relevance, groundedness, and answer relevance), is emphasized as essential. A significant production challenge identified is "speed," underscoring the growing importance of smaller, efficient LLMs.

Transformers, highlighted in the 2017 paper "Attention Is All You Need," are central to Large Language Models (LLMs) that predict the next token in a sequence. The process involves tokenizing input (e.g., text into words/sub-words), then embedding these tokens into high-dimensional vectors representing their meaning and position. These vectors flow through multiple layers, each consisting of an "attention block" and a "multi-layer perceptron" (MLP). The attention block allows token vectors to "talk" and exchange contextual information, while the MLP incorporates learned world knowledge. This iterative refinement enables the final token's vector to predict a probability distribution for the next token. Training optimizes billions of parameters using gradient descent, minimizing a cost function (e.g., negative log probability of the correct next token) on extensive datasets.
The "attention" mechanism is key: each token generates a "query" (what it's looking for), a "key" (information it offers), and a "value" (its content) via learned matrices. Dot products between queries and keys determine relevance, which softmax converts into attention weights. These weights guide a sum of value vectors to update the querying token's embedding, enriching it with context. "Multi-headed attention" executes this in parallel with different matrices, capturing varied relationships. Causal masking during training ensures tokens only see past information, vital for efficient parallel training. The highly parallelizable nature of these matrix operations makes Transformers ideal for GPUs, driving their scalability and performance. Grant Sanderson emphasizes understanding these computations and their parallel nature as fundamental to Transformer success, allowing them to process vast contexts and store extensive knowledge.

Airbnb addresses the complexity of its Homes search—navigating millions of listings and intricate queries like flexible dates—by implementing an Embedding-Based Retrieval (EBR) system. This system's primary goal is to efficiently narrow down a vast pool of eligible homes into a smaller, more manageable set for subsequent, compute-intensive machine learning ranking models. The development journey centered on three core challenges: constructing effective training data, designing a scalable model architecture, and establishing an efficient online serving strategy using Approximate Nearest Neighbor (ANN) solutions. Key to training was a contrastive learning approach, leveraging user trip data to define positive (booked) and crucial negative (seen/interacted with but not booked) home pairs, avoiding the pitfalls of random negative sampling.
The model architecture employed a two-tower network, separating offline-computed listing embeddings from real-time query embeddings for low latency. For online serving, Airbnb selected Inverted File Index (IVF) over HNSW, as IVF better handled frequent listing updates and geographic filters, offering a superior speed-performance trade-off. A significant insight was that using Euclidean distance (over dot product) as the similarity metric resulted in more balanced IVF clusters, critical for retrieval accuracy. This EBR system achieved a statistically significant increase in overall bookings, comparable to major ML ranking enhancements, by effectively incorporating query context to surface more relevant results, particularly for broad searches.
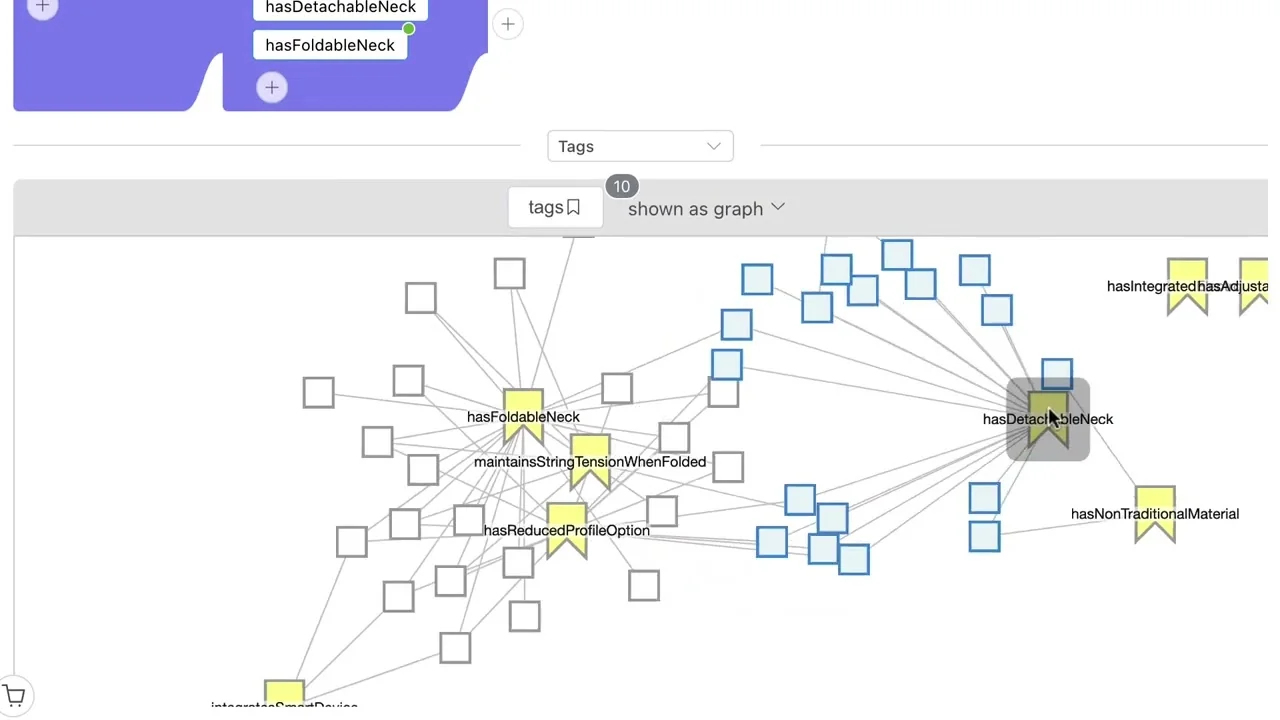
This video demonstrates how Large Language Models (LLMs) can enhance search by dynamically adding structure to raw text at query time. Using patent data for "travel guitars" as an example, it illustrates how LLMs overcome limitations of existing structured metadata (e.g., patent category codes) that may lack granularity. The LLM analyzes search results to generate subject-specific tags like "has detachable neck" or "has foldable neck," providing justifications by extracting relevant text snippets from source documents. In the video, Mark notes the LLM is "analyzing the text and...coming up with what it thinks are useful categorizations."
A key feature is dragging these dynamic tags into a query builder for rapid search refinement (e.g., finding travel guitars that have a "detachable neck OR foldable neck"). Visualizations like tables and graph views aid exploration. An insightful LLM-identified tag is "maintaining string tension when folded," a crucial feature for travel guitars ensuring they are "quickly redeployed for playing without lengthy retuning." These tags are initially session-specific, "a perspective and a way of tagging documents that doesn't necessarily require me to reindex the data," offering powerful exploration. However, sharing or permanently indexing these tags are further considerations.