 Kobi Lemberg
Kobi Lemberg
How to safely sequence Alembic migrations ahead of ECS rolling deployments using ECR EventBridge events, Step Functions, and digest-pinned Fargate tasks - no CI runner required after the image push.
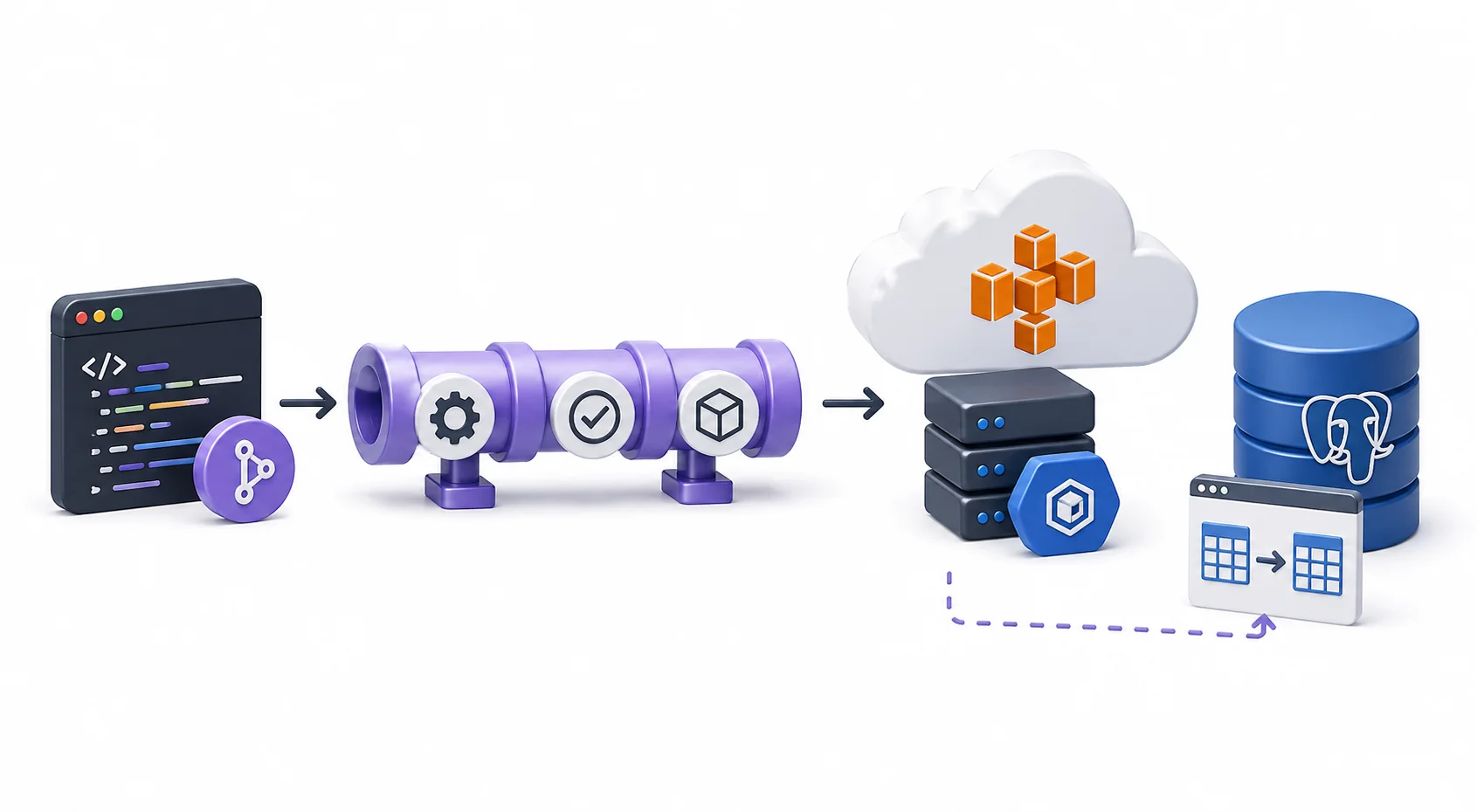
Running database migrations safely during a zero-downtime deployment looks straightforward until you've been paged at 2am because a new container started before the migration finished, the schema was in a half-applied state, and half your requests were 500ing. The root cause is always the same: ECS has no built-in gate between "new image available" and "new tasks serving traffic."
The Problem: Schema Changes and Rolling Deployments
Most non-trivial application updates eventually require a database schema change - a new column, a renamed table, a new index, a backfilled constraint. On ECS, the default deployment model is a rolling update: ECS gradually replaces tasks running the old image with tasks running the new one, while both versions briefly serve traffic side by side. That works beautifully for stateless code changes. It breaks down the moment the new code expects a schema the database does not yet have - or the old code is still running against a schema that has already been altered underneath it.
The classic answer is a migration tool that versions schema changes as ordered scripts. In the Python ecosystem, Alembic is the de facto choice, typically paired with SQLAlchemy. Each migration is a revision with upgrade and downgrade steps; Alembic tracks which revisions have been applied via an alembic_version table in the target database, and alembic upgrade head brings the schema up to the latest revision. Other ecosystems have direct equivalents (Flyway, Liquibase, Rails migrations, Django migrations, Knex, golang-migrate) and the architecture in this post applies to all of them - we use Alembic as the running example.
The hard problem is not "how do I run the migration." It is "how do I guarantee the migration runs exactly once, finishes successfully, and only then lets the new image start serving traffic - and if it fails, leaves the existing service untouched." This post walks through an event-driven architecture that gives you that guarantee: ECR push fires an EventBridge event, a Step Functions state machine takes over, a dedicated one-shot migration task runs to completion, and the ECS service is only updated if that task exits clean.
The Architecture
The core idea is simple: a dedicated, single-instance migration task runs to completion before the application service is upgraded. Not as an init container alongside the app, not from CI, not in parallel with rolling tasks - a separate Fargate task, pinned to the exact same image digest as the upcoming app deployment, that does one thing and exits. Only on a clean exit does the orchestrator move on to update the ECS service. This separation is what makes the rest of the design work.
The orchestrator itself is a Step Functions state machine. Here is the high-level flow:
ECR push (:latest)
→ EventBridge rule (image push event, contains image digest)
→ Step Functions state machine
→ Lambda: RegisterTaskDefs
→ ECS RunTask: migration task (digest-pinned)
→ Wait for STOPPED (ecs:runTask.sync)
→ [exit 0] ECS UpdateService (new app task def revision)
→ [exit !=0] State machine fails; service unchanged
The key property of this design is that CI is done after the image push. In a typical setup, the CI pipeline ends with an aws ecs update-service call to trigger a rolling deployment - we remove that entirely. Instead, ECR natively emits an EventBridge event on every successful image push, which forwards to the state machine. From this point, the deployment lifecycle is owned by Step Functions. No CI runners stay alive waiting for AWS, no polling loops.
Why the Naive Patterns Break
To understand why this matters, it's worth looking at how ECS rolling deployments normally work. When you call aws ecs update-service, you're telling ECS to replace running tasks with a new task definition revision. ECS drains old tasks from the load balancer and starts new ones, respecting the minimumHealthyPercent and maximumPercent deployment configuration. The command itself returns immediately - the deployment is scheduled, not complete.
For stateless apps with no schema changes, this is fine. Once you add database migrations to the picture, the timing gap becomes a problem.
The CI migration race
Running alembic upgrade head from CI before triggering the service update seems like it should work. In practice, the race window is wider than expected. Aggressive minimumHealthyPercent settings allow ECS to start new tasks before a migration script completes. If the migration fails midway, the CI job errors out but ECS may have already partially replaced tasks with the new image, leaving some tasks running new code against a schema that isn't fully updated.
The init container trap
ECS container dependencies let you run a migration container before the app container starts, using dependsOn with the SUCCESS condition. This works for a single task - but ECS services run multiple tasks, and a rolling deploy replaces them in parallel.
With 10 running tasks, 10 migration containers start simultaneously, all calling upgrade head against the same database. Alembic tracks state with a conditional UPDATE alembic_version SET version_num='new_rev' WHERE version_num = 'old_rev', but this provides no blocking protection against concurrent processes. The Alembic maintainers have explicitly declined to add built-in distributed locking, calling it "too complicated, error prone, and hard to maintain across database backends." You can add PostgreSQL advisory locks in env.py, but that's working around a fundamental architectural mismatch.
Pattern comparison
| Pattern | Migration runs once? | Failure blocks deploy? | CI runner required? |
|---|---|---|---|
CI script + update-service |
Yes | No (race condition) | Yes, stays alive |
| Init container per task | No (N concurrent) | Partial | No |
| Step Functions orchestration | Yes | Yes | No |
The Step Functions approach is the only one that gives you a hard sequencing guarantee: the new image never serves traffic until one migration task has exited with code 0.
Walking Through Each Step
Step 0: ECR push and EventBridge
CI builds and pushes the image to ECR. That's its last action. An EventBridge rule filters for action-type: PUSH and result: SUCCESS on the target repository, and starts a Step Functions execution with the push event as input.
ECR natively emits an ECR Image Action event on every successful push. The payload includes the image digest:
{
"detail-type": "ECR Image Action",
"source": "aws.ecr",
"detail": {
"result": "SUCCESS",
"repository-name": "myapp",
"image-digest": "sha256:7f5b2640fe6fb4f46592dfd3410c4a79dac4f89e4782432e0378abcd1234",
"action-type": "PUSH",
"image-tag": "latest"
}
}
That image-digest is the sha256 of the image manifest - immutable and exact. Every subsequent step in the state machine references this digest, not the :latest tag.
Step 1: RegisterTaskDefs Lambda
The first state invokes a Lambda that registers two new ECS task definition revisions, both pinned to the exact digest from the EventBridge payload:
- App task definition - the web service task, same as before but image set to
repo@sha256:... - Migration task definition - same image and digest, different command, different secrets, no load balancer integration
Before doing any of this, the Lambda checks for concurrent executions. It calls sfn:ListExecutions on the state machine with status RUNNING. If any other execution is in flight (excluding the current one), it raises ConcurrentDeployment and aborts. Without this guard, two rapid image pushes would kick off two parallel state machines, both running migrations against the same database and then racing to update the service.
The digest is embedded in the image reference as:
123456789.dkr.ecr.us-east-1.amazonaws.com/myapp@sha256:7f5b2640...
ECS ignores the tag when a digest is present in the image string. This format locks the task definition to exactly one image, forever.
Step 2: Run the migration task
This is the heart of the design: a dedicated migration task is launched and must finish successfully before the app service is touched. The state machine uses the ecs:runTask.sync Step Functions-ECS integration to launch the migration task and wait for it to complete. This is a managed integration pattern: Step Functions creates an internal EventBridge rule (StepFunctionsGetEventsForECSTaskRule) to receive task state change events from ECS, so it's event-driven rather than polling.
The migration task definition is configured with:
- Command override: the entry point that runs
alembic upgrade head(or equivalent for your migration framework), rather than the normal app startup command - Master DB credentials via ECS secrets (Secrets Manager) - the migration task needs DDL permissions; app tasks use a lower-privileged application user
- Any background workers or schedulers disabled via environment variable - you want the container to do one thing only: connect to the database, run migrations, and exit
The task has no port mappings and no ALB target group association. It runs your migrations, exits, and that's it.
Step 3: Check exit code and update service
Step Functions checks the task exit code via a Choice state:
- Exit code 0: proceed to
UpdateServicewith the new app task definition revision (the one registered in Step 1, digest-pinned) - Any other exit code: transition to a Fail state. The ECS service is not touched. The old tasks keep running.
Migration failure means the deploy is blocked. The currently-running app tasks - still on the old revision - keep serving traffic. No partial state, no new code against an incompatible schema.
Key Design Decisions
Digest pinning, not tag pinning
Image tags are mutable. In the window between an EventBridge event and when ECS actually pulls the image for the service update, a subsequent push could change what :latest resolves to. You'd run migrations for image A and deploy image B.
Digest pinning eliminates this. The sha256 digest is a content hash of the image manifest - it cannot change. Once registered, repo@sha256:abc123... will always pull exactly that image. This also makes rollbacks deterministic: any previous task definition revision pulls the exact code it was registered with.
AWS introduced automatic software version consistency for ECS services in July 2024, which captures the digest from the first task launched in a deployment and pins all subsequent tasks to it. That's a useful backstop, but it doesn't help you for the migration-before-deploy problem. Explicit digest pinning in the task definition gives you the same guarantee for the migration task, which runs before the service is updated.
Dedicated migration task definition
Keeping a separate migration task definition (rather than an init container) has concrete benefits:
Credential isolation. The migration task gets master DB credentials with DDL permissions. App tasks use a lower-privileged user. This is proper least-privilege - your web service doesn't need ALTER TABLE.
One run, one outcome. The migration task runs exactly once per deployment. No concurrent Alembic processes, no advisory lock gymnastics, no ambiguous state.
Observability. The migration task appears as a discrete entry in ECS task history with its own CloudWatch log stream. You can see exactly what Alembic ran, read the output line by line, and diagnose failures without sifting through app logs.
Scheduler isolation. Disabling background workers and schedulers via environment variable ensures nothing else runs in the container. It connects to the database, applies migrations, and exits with a clear status code.
Alembic and DDL locking
Even with a single migration process, DDL operations can cause brief unavailability. PostgreSQL DDL statements (ALTER TABLE, CREATE INDEX) acquire ACCESS EXCLUSIVE locks that block all reads and writes. Once a DDL statement enters the wait queue, it blocks all subsequent queries - even SELECTs - creating a cascading queue. For busy tables, this can translate to application errors.
Two settings help significantly: setting lock_timeout = 4000 (4 seconds) in the migration session causes the DDL to fail fast with a lock_not_available error rather than holding up the whole application, and implementing retry logic in env.py. For index creation, use CREATE INDEX CONCURRENTLY - Alembic supports this via transaction_per_migration=True in the migration context since CONCURRENTLY cannot run inside a transaction.
Fully serverless orchestration
Removing update-service from CI was deliberate. When CI drives the deploy, the job has to stay alive while waiting for service stabilization - or fire-and-forget and lose a reliable failure signal. With Step Functions:
- CI is fast and stateless: build, push, done
- Deployment history is tracked per-execution in Step Functions, with per-state timing and input/output
- Failures surface as Step Functions execution failures with full logs, not mysterious ECS deployment events
- Re-driving a failed deployment means starting a new state machine execution, not re-running CI
Terraform Skeleton
The key resources are an ECR repository with an EventBridge rule, the Step Functions state machine (Amazon States Language), a Lambda for RegisterTaskDefs, and two ECS task definitions.
The migration task definition:
resource "aws_ecs_task_definition" "migration" {
family = "myapp-migration"
requires_compatibilities = ["FARGATE"]
network_mode = "awsvpc"
cpu = 512
memory = 1024
execution_role_arn = aws_iam_role.ecs_execution.arn
task_role_arn = aws_iam_role.migration_task.arn
container_definitions = jsonencode([{
name = "migration"
image = "${aws_ecr_repository.app.repository_url}:latest" # overridden at runtime with digest
command = ["python", "-m", "myapp.migrate"] # your migration entrypoint
environment = [
# disable any background workers/schedulers your app normally starts
{ name = "BACKGROUND_WORKERS_ENABLED", value = "false" }
]
secrets = [
# use master/DDL-privileged credentials, not the app user
{ name = "DATABASE_URL", valueFrom = aws_secretsmanager_secret.db_master.arn }
]
logConfiguration = {
logDriver = "awslogs"
options = {
awslogs-group = "/ecs/myapp-migration"
awslogs-region = var.aws_region
awslogs-stream-prefix = "migration"
}
}
}])
}
The image field in the static Terraform definition doesn't matter - the Lambda overrides it with the digest-pinned reference when calling register_task_definition at deploy time.
The Step Functions IAM role needs these permissions for the ECS integration:
{
"Action": ["ecs:RunTask"],
"Resource": "arn:aws:ecs:*:*:task-definition/myapp-migration:*"
},
{
"Action": ["ecs:StopTask", "ecs:DescribeTasks"],
"Resource": "*"
},
{
"Action": ["events:PutTargets", "events:PutRule", "events:DescribeRule"],
"Resource": "arn:aws:events:*:*:rule/StepFunctionsGetEventsForECSTaskRule"
},
{
"Action": ["iam:PassRole"],
"Resource": [
"${aws_iam_role.ecs_execution.arn}",
"${aws_iam_role.migration_task.arn}"
]
}
The iam:PassRole permission is required so Step Functions can pass the execution and task roles to ECS when launching the migration task. Missing it is a common deployment error that shows up as an AccessDenied on the RunTask call.
Summary
After shipping this, the deployment workflow from an engineer's perspective is:
- Merge to main
- CI builds and pushes the image - takes a few minutes, then it's done
- Step Functions picks up the ECR event automatically
- Migration task runs; watch it in ECS task logs / CloudWatch
- If migrations pass, the ECS service updates and new tasks roll out
- If migrations fail, you get a Step Functions execution failure, the old service keeps running, and you have a clean log of what went wrong
Key takeaways:
aws ecs update-servicetriggers a rolling deployment asynchronously and returns immediately. It provides no migration sequencing guarantee. Remove it from CI and let Step Functions own the deployment lifecycle.- Init containers create N concurrent Alembic processes per rolling deploy. Alembic has no built-in distributed locking.
- ECR push events include the image digest in the EventBridge payload. Use it to pin both the migration task and the app task definition to the same exact image.
ecs:runTask.syncblocks the state machine until the Fargate task reaches STOPPED, using internal EventBridge rules - no polling overhead.- A dedicated migration task definition gives you credential isolation, single-execution semantics, and clean per-deployment log streams.
- Setting
lock_timeoutin the Alembic migration session prevents DDL operations from cascading into full application outages on busy tables.
The architecture adds operational surface area - you need the state machine, Lambda, EventBridge rule, and migration task definition working correctly. For any application where migrations are part of the deployment process, that surface area is worth it. The alternative is carefully writing every schema change to be backward-compatible with the currently-deployed code, which works but imposes its own ongoing complexity tax on the development team.
One last thing: take a backup
A note that should not need stating but does: always take a database backup immediately before a deployment that runs migrations. The architecture above gives you strong sequencing guarantees - migrations run once, failures block the deploy, the old service keeps serving traffic - but none of that protects you from a migration that completes "successfully" and silently corrupts data, drops the wrong column, or applies a destructive change that turns out to be wrong in production. Snapshots are cheap, restores from a known-good point are not. Whether it is an automated RDS snapshot triggered as the first state in the state machine, a logical dump, or a point-in-time-recovery window you have verified, make sure there is a clean restore target before the migration task starts. You can never be too careful with schema changes.

