Liza Katz
Liza Katz
Long context windows don't solve retrieval. They introduce lost-in-the-middle effects that silently degrade answers. We cover Effective Context Length, chunking strategies, and the retrieval patterns that work in production RAG systems.

Introduction: The Pirate's Dilemma
Imagine you are a pirate captain. You have just stolen a 500-page leather-bound book titled The Comprehensive Geography of the Caribbean. Somewhere inside this boring text, a rival pirate has hidden the location of a treasure. You wish to find it.
This is the classic "Needle in a Haystack" problem in one paragraph.
In the world of Large Language Models (LLMs), your "context window" is the pirate's capacity to read that book. Intuitively we might assume that as long as the book fits in the pirate's hands (the context window), they would find the treasure.
But it turns out, pirates - and LLMs - get bored.
If the treasure map is on Page 1 (Primacy Bias), they find it. If it’s on the last page (Recency Bias), they find it. But if you bury that single sentence on page 250, right in the middle of a chapter about banana exports? The pirate might glaze over it and the treasure stays lost.
Part 1: The "Green Square" Illusion
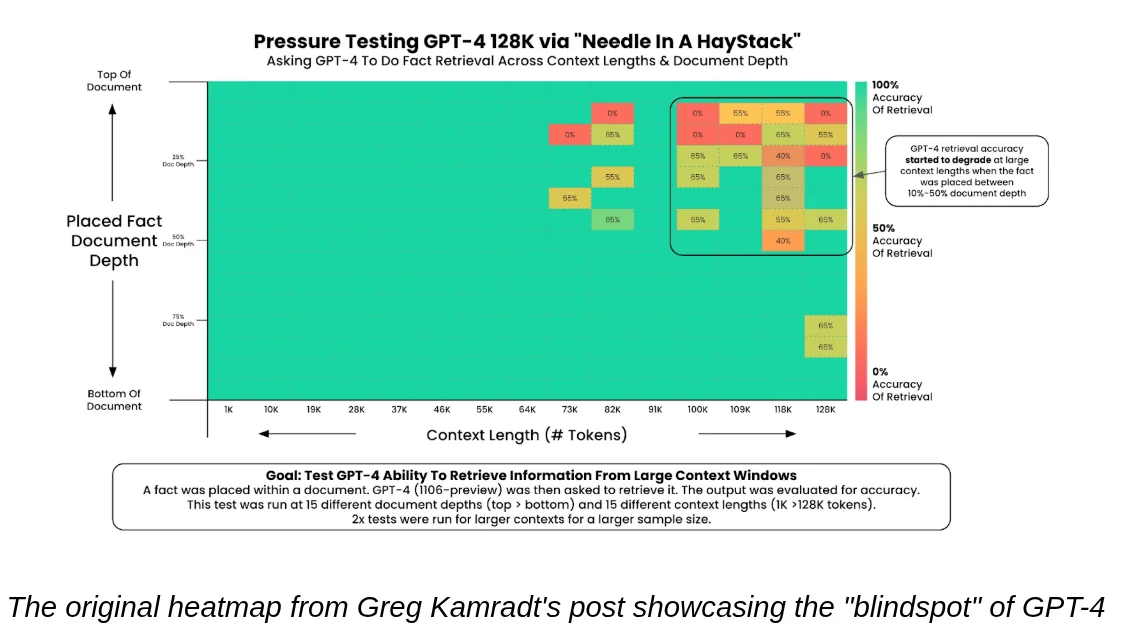
In 2023, this "Lost in the Middle" phenomenon (coined by Liu et al.) was the bane of RAG systems. It was visualized using the "Needle in a Haystack" Heatmap by Greg Kamradt.
- X-Axis: How long the book is.
- Y-Axis: Where the treasure is hidden (Top, Middle, Bottom).
- The Result: A nasty red area across the middle.
But that was ages ago (or in AI years, a little over a year). If you look at the marketing for modern models, they all claim to have "solved" this, boasting context windows of 128k, 1M, or even 2M tokens.
If you run that same simple "find the treasure" test today, the heatmap looks like this:
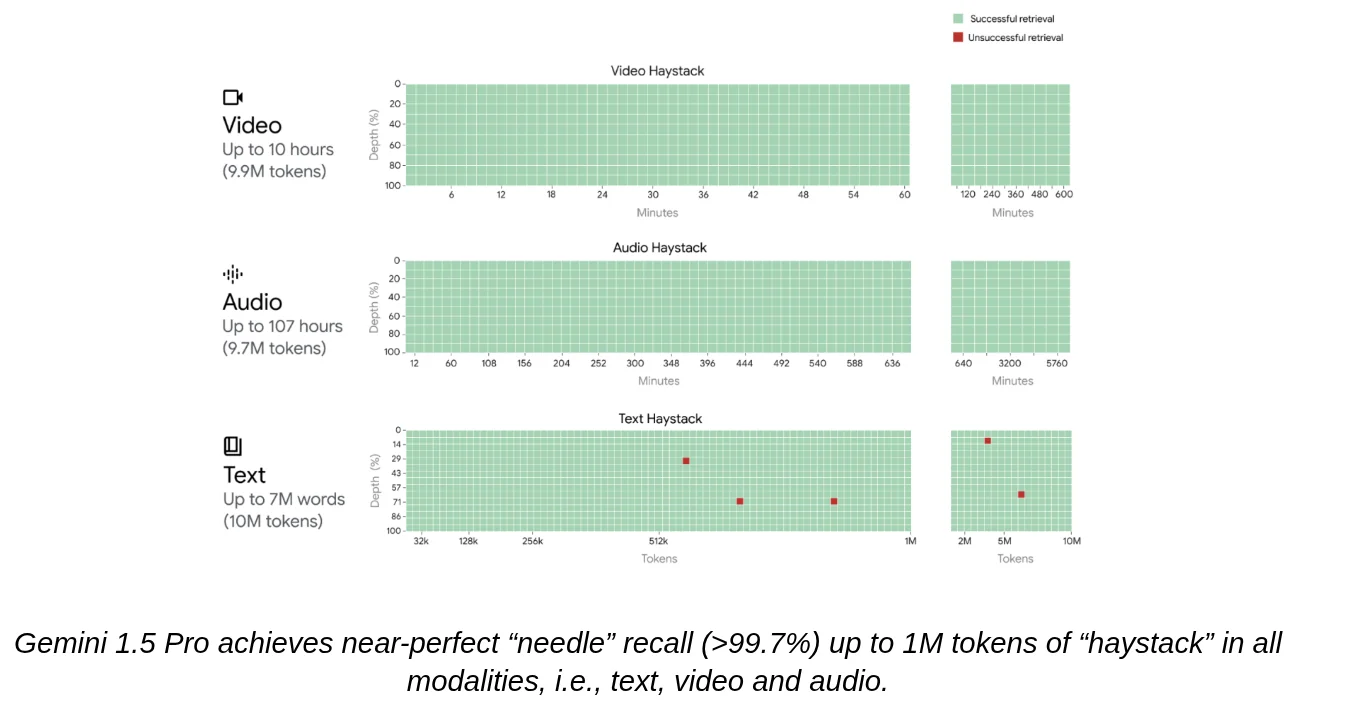
It’s a nearly perfect green field. Problem solved, right? Can we all go home?
Part 2: Why the Green Square is a Lie
Anyone who has actually put a long-context RAG system into production knows that the "Green Square" is deceptive. It measures the absolute easiest task: retrieving a single, distinct fact.
But real-world RAG isn't about finding one sentence. It’s about data synthesis**.** The "Green Square" starts to turn red the moment you add more complexity:
Multiple Needles: You aren't just looking for the treasure location. You ask: "Where is the treasure, what tools do I need to dig it up, and is the island inhabited?" Now the model has to hold three distinct questions in memory simultaneously.
Conflicting Information: Page 10 says "The treasure is on Skeleton Key," but a note on Page 400 (dated 2025) says "The treasure was moved to Dead Man's Chest." Simple retrieval might give you the first one. A smart system needs to understand the temporal relationship.
Reasoning Chains: The text doesn't say where the treasure is. It says: "The treasure is in the Red Box." Later, it says "The Red Box is in the Cave." Finally, it says "The Cave is behind the Waterfall." To answer "Where is the treasure?", the model must connect A $\rightarrow$ B $\rightarrow$ C across thousands of tokens of noise.
Part 3: Measuring the Mess
So, how do we measure this "real" performance? We need a benchmark that is harder than a simple treasure hunt.
Side Note: At this point, AI has more benchmarks than a JavaScript project has node_modules. Picking a single truth one is hard, but different benchmarks show similar results.
One such benchmark is RULER (developed by NVIDIA and partners). It’s not a single test; it’s a torture suite for LLMs. Including things like:
- Retrieval: The “basic” needle-in-a-haystack test, but with multiple types and quantities of needles.
- Multi-hop Tracing: Tests reasoning chain like Connecting the Red Box -> Cave -> Waterfall to find the treasure
- Aggregation: Find the 10 most common words in a document
- And 10 other benchmarks taking the LLM to the edge.
And we can then run these tests at increasing lengths, from 4k to 128k, and watch the score drop.
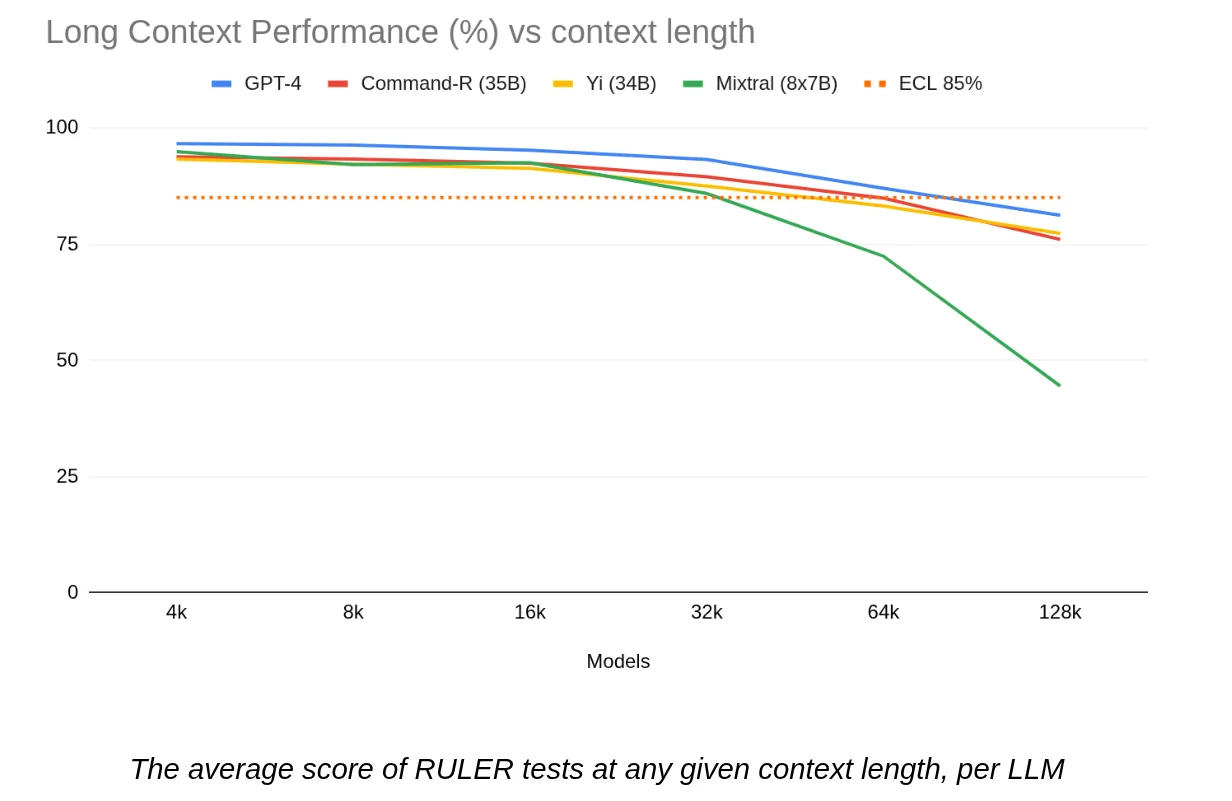
The Metric: Effective Context Length (ECL)
This comes to show that we shouldn’t care what the marketing says the context length is. We should care about the Effective Context Length (ECL).
This is the maximum context size where the model maintains a performance score of at least 85% (or your chosen threshold) relative to its baseline.
Most models hold up well until 32-64 tokens, then things might look shaky. This is the number you should use when designing your RAG, not the number on the box.
Part 4: What can you do about it?
So your ECL is lower than you hoped. Your pirates are losing the treasure in the middle of the book. What now?
1. Pick a Better LLM (The "Brute Force" Solution)
Sometimes, upgrading works. It seems like newer models tend to have higher ECLs.
However, "Reasoning" models paradoxically tend to underperform in vague situations. Recent evaluations show that heavy reasoning models can sometimes overthink simple extraction tasks, hallucinating details that aren't there, or they simply cost 10x more and take 10x longer for the same result in the best case.
2. Break Down the Flows
If you are looking for multiple needles, don't ask for them all at once.
- Bad: "Find the location, the tools, and the weather."
- Good: Run three parallel calls (or a sequential chain). This keeps the attention mechanism focused on one task at a time. It adds latency, but it drastically improves recall for "middle" information.
3. Improve Your Retrieval
The best way to fix a context problem is to have less context.
- Aim for high precision/low recall in your vector search.
- Don't dump 50 documents into the context if the answer is likely in the top 3.
4. Format for the Machine
Help the model ignore the noise.
- Enrich Metadata: If your document has a temporal element (like our 2023 vs 2025 treasure note), explicitly inject [Date: 2025-01-01] into the text chunks. It makes the "needle" shine brighter against the "haystack."
5. The Reranker
Use a reranker model or a cheap LLM (like Claude Haiku or GPT-minis) as a reranker inside the context.
- Instead of asking the LLM to "Answer the question," ask it to: "Return the IDs of the 3 paragraphs most relevant to this question."
- Why? It forces the model to scan the whole context without the burden of generating natural language. It’s faster, cheaper, and often more accurate. Once you have the indices, you pass only those paragraphs to your expensive model for the final answer.
Conclusion
The "Green Square" era of context evaluation is over. As we build agents that need to reason, compare, and aggregate, we have to acknowledge that order still matters. Measure your own Effective Context Length, don't trust the marketing numbers, and remember: X marks the spot, but only if your pirate is paying attention.