 Itamar Syn-Hershko
Itamar Syn-Hershko
Why accuracy fails in search and RAG pipelines. Explore precision, recall, and the tradeoffs that shape agentic retrieval systems.

We live in an age of algorithms making countless decisions that affect our daily basis. From determining which emails land in your spam folder to diagnosing medical conditions, from approving loan applications to recommending what you watch next on Netflix - machine learning models are quietly working behind the scenes, making predictions and classifications at unprecedented scale.
When we hear about these systems, the conversation often centers on one simple question: “How accurate is it?” We're told that a model is “95% accurate” or “outperforms humans” and we assume that higher accuracy automatically means better performance. It's an intuitive way to think about it - after all, being right more often seems obviously better than being right less often.
But here's the problem: accuracy alone can be misleading.
Why Accuracy Falls Short: The Hidden Problems
For the sake of the example, imagine you’re building a model to detect a rare disease that affects only 1 in 1000 people. A model that predicts that no patient can catch this disease will achieve an accuracy of 99.9%. Yet, this model would be completely useless, missing every single person who actually needs a treatment for this disease.
If we further dive deeper into issues in accuracy, we can observe that not all the mistakes created by the model are equal. For instance, in medical diagnosis, missing a cancer case could be fatal while incorrectly recommending a healthy patient for additional testing is only considered inconvenient.
To understand why accuracy misleads us, we need to look beyond this metric and examine four fundamental outcomes that occur when any machine learning model makes a prediction.
The Building Blocks: Understanding True/False Positives and Negatives
To better understand each of the building blocks, let’s use an example we can relate to: email spam detection. Every time your email system makes a decision about whether an incoming email is a spam or not, one of the four things happen:
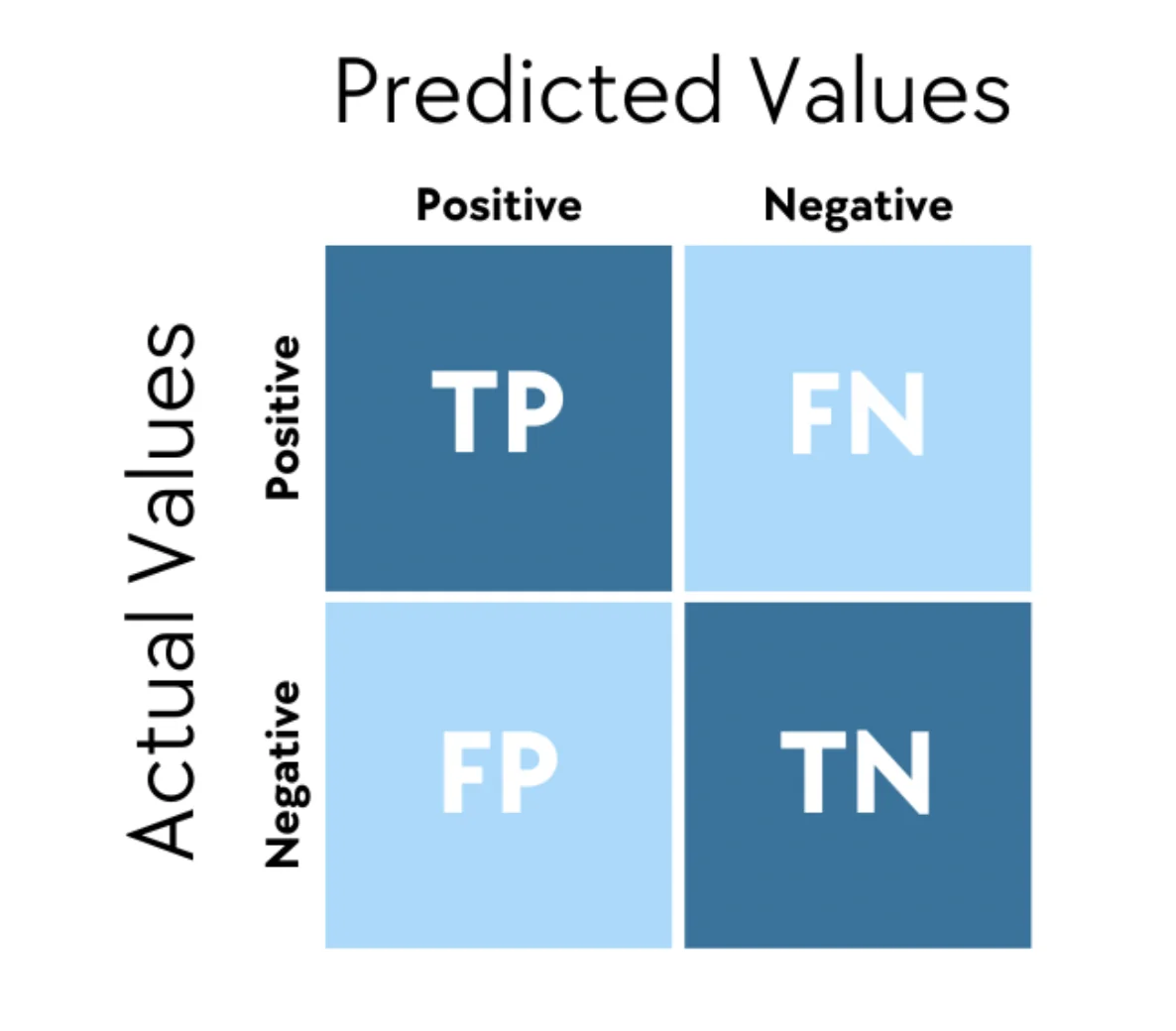
True Positives (TP) - The received email is a spam and your system correctly detected it as a spam.
True Negatives (TN) - The received email is not spam and your system correctly detects it as a safe mail. The negative term represents the complementary scenario in our use case (not spam).
False Positives (FP) - The received email is not spam, however your system incorrectly detects it as spam. Not focusing on lowering the FP value may cause your system to ignore critical emails arriving into your inbox.
False Negative (FN) - The received email is a spam, however your system incorrectly detects it as no spam. This can result in an uncomfortable situation where your inbox is filled with scam emails.
One way of presenting the above values is by using a confusion matrix:
Understanding Precision and Recall
After we better understand the building blocks, we can construct two powerful metrics that give us a much clearer picture of our model’s performance than accuracy alone. Precision and Recall answers the following questions:
Precision asks: “When my model claims that something is positive, how often is it actually right?”
In our spam example, precision tells us: of all the emails your system flagged as spam, what percentage were actually spam?
The formula of precision is given in eq.(1):
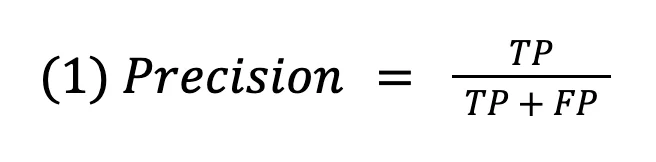
If your spam filter has high precision, you can trust that when it sends something to your spam folder, it probably belongs there. If your spam filter has low precision, many legitimate emails are flagged as spams.
Recall asks: “Of all the actual positives out there, how many did my model successfully catch?”
In our spam example, recall tells us: of all the spam emails that came in, what percentage did your filter actually catch?
The formula of recall is given in eq.(2):
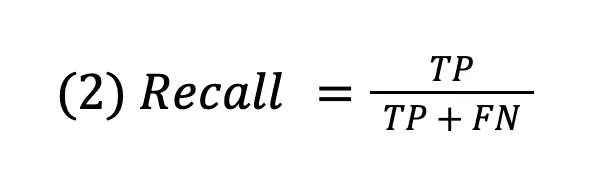
High recall means our filter is excellent at catching spam and low recall means instead of filtering out spam emails, many of them are being considered as legitimate and end up in your inbox.
The Inevitable Tradeoff: Why You Can't Have Both
The relationship between precision and recall are a fundamental characteristic of machine learning that determines how our models make decisions.
Every model has an internal confidence threshold, and adjusting this threshold creates the following effect: lower it to catch more positives (improving recall) and you'll inevitably catch more false alarms too (hurting precision)
If you raise it, you avoid false alarms (improving precision) and you'll miss more real positives (hurting recall).
In Summary
The next time someone proudly announces that their AI model is 95% accurate, you'll know to ask the more important questions: What's the precision? What's the recall? What kind of mistakes is it making, and do those mistakes matter for the specific problem we're trying to solve?
Understanding precision and recall doesn't just make you a more informed consumer of AI claims - it fundamentally changes how you think about machine learning performance.

