 Itamar Syn-Hershko
Itamar Syn-Hershko
A consulting-grade reference for production RAG pipelines: nine stages from ingestion to evaluation, anchored on OpenSearch hybrid search, with orchestration framework trade-offs and a production readiness checklist.
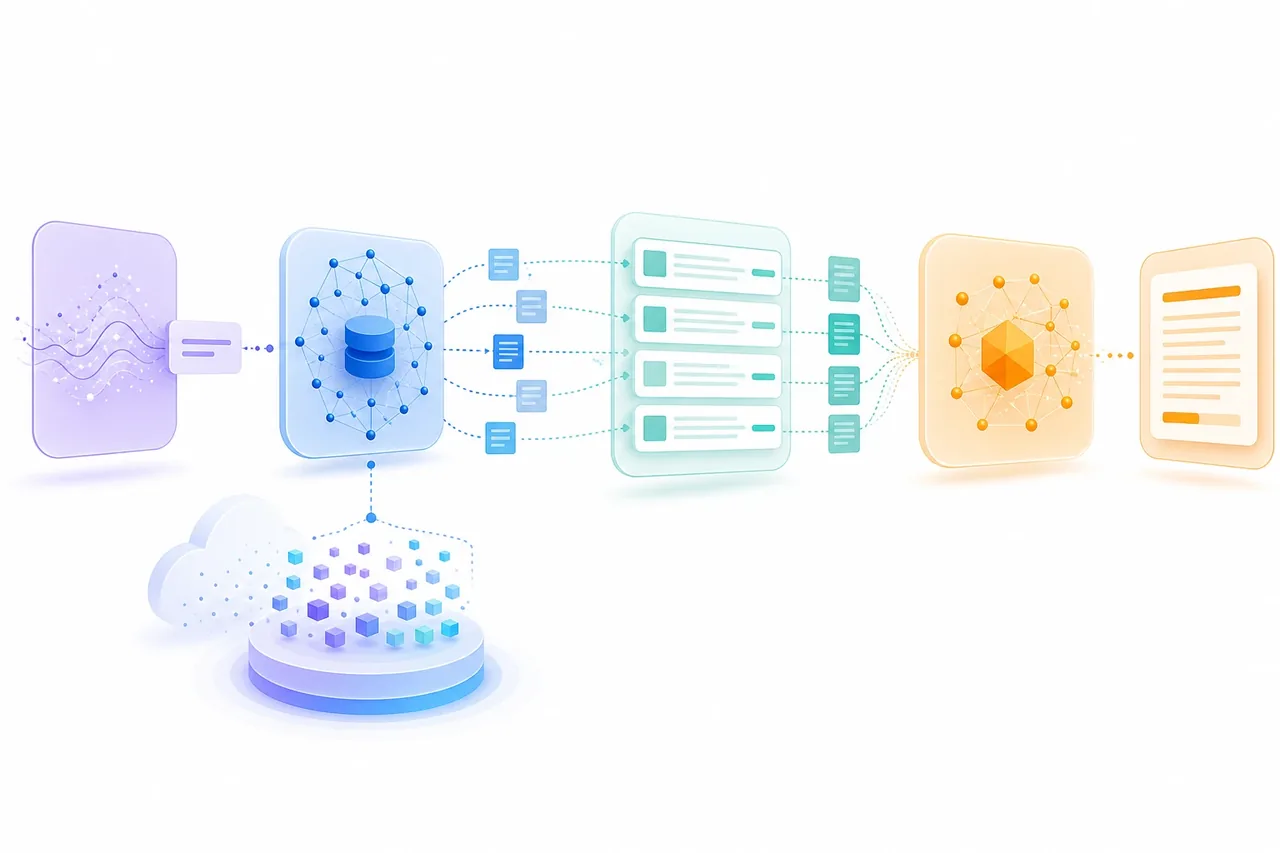
Notebook RAG works on ten documents. Production RAG breaks at a hundred thousand, where stale indexes drift, permission leaks turn into breach reports, and silent retrieval degradation poisons answers nobody is auditing. The gap between the demo and the ship is a pipeline - nine distinct stages, each a place where a separate decision lives, each independently testable and replaceable. Anchoring the whole thing on OpenSearch gives you one system that handles the lexical and the dense vector sides without the coordination tax of running two stores.
This guide is the architecture we recommend to teams shipping production RAG: the nine stages, the trade-offs at each, the orchestration framework that fits the shape of your team, and the readiness checklist before any of it goes live.
Why Pipelines, Not Notebooks
Five failure modes recur in consulting engagements, and all of them trace back to a missing pipeline stage:
- No reindexing strategy. Documents change. If your pipeline cannot detect updates and propagate them, every answer eventually drifts.
- Permission leaks. ACLs were never captured at ingest, so retrieval surfaces documents the requesting user should not see.
- Pure-vector recall gaps. Dense embeddings miss exact entity names, IDs, and acronyms - the single thing the user actually typed.
- No eval gates. A chunking change ships, retrieval quality silently drops 8 NDCG points, nobody notices until the support queue spikes.
- Unobservable retrieval. Latency is logged. Recall is not. You cannot debug what you cannot measure.
A production pipeline must guarantee deterministic reprocessing on source change, ACL propagation from source to response, measurable retrieval quality with CI gates, and cost and latency budgets enforced through caching and async patterns. Each stage below maps to one of those guarantees.
The high-level shape:
Source → Ingestion → Parsing → Chunking → Embedding → Indexing (OpenSearch)
│
▼
User Query → Hybrid Retrieval (BM25 + k-NN) → Rerank → Generate → Response
│
▼
Eval / Observability / Online Sampling
Stage 1: Ingestion and Connectors
Ingestion is where documents enter the system, and where ACLs are captured. The unforgivable mistake is treating access control as a Stage 5 problem - it is not. Source permissions (Active Directory groups, Confluence space ACLs, SharePoint sharing rules, S3 prefix policies) must become first-class metadata fields the moment a document arrives. Retrofitting is architecturally expensive and prone to gaps.
Connector patterns split into pull (scheduled crawls) and push (webhooks, change-data-capture). Pull is simpler; push is what you want for any source that supports it, because it gives you incremental, near-real-time updates and tombstone handling for deletes. Idempotent processing is mandatory - assume at-least-once delivery and design the downstream stages to deduplicate.
Managed alternative: AWS Bedrock Knowledge Bases handles connector orchestration, parsing, and indexing with less operational ownership, at the cost of less control over chunking and reranking specifics. The chunking and embedding details are documented separately under "How knowledge bases work."
Stage 2: Parsing and Normalization
Parsing is its own stage because chunking quality is bounded by parse quality. Garbage in, garbage out. PDFs with multi-column layouts, embedded tables, scanned images, and Office documents demand specialised tooling - a generic text extractor will silently merge column text or skip table rows.
The 2026 toolset:
- Unstructured.io - element-level extraction (Title, NarrativeText, Table, Image), open-core, broad format support.
- LlamaParse - cloud-hosted, strong on complex PDFs, returns markdown.
- Azure Document Intelligence - enterprise OCR plus layout, integrates well in Azure-heavy stacks.
- Docling (IBM) - open-source, document-structure-aware, particularly strong on scientific papers.
Normalisation strips boilerplate (headers, footers, navigation), extracts title, date, author, and section hierarchy as structured metadata, and decides what to do with non-text. Tables typically convert to markdown for LLM-friendly downstream prompts; images either get captioned by a VLM or skipped depending on whether the corpus is figure-heavy.
Stage 3: Chunking
Chunk size is one of the highest-leverage knobs in the pipeline. Too small and context is lost; too large and irrelevant tokens dilute the signal. Empirically 256-512 tokens covers most cases, with 10-20% overlap to prevent boundary information loss. Code, legal, and clinical text often warrant larger chunks.
Beyond fixed and recursive splitting, two 2024-2025 techniques materially improve recall:
- Anthropic Contextual Retrieval (Sept 2024) prepends a one-to-two sentence context summary to each chunk before embedding and BM25 indexing. Anthropic's own evaluation shows the technique cuts top-20 retrieval failure rate by 49% versus a baseline (5.7% to 2.9%); pairing it with reranking pushes the reduction to 67%.
- Late chunking embeds the full document with a long-context encoder, then segments after embedding. This preserves cross-chunk context that local-window encoders lose.
Layout-aware chunking - using parse-stage structure (headings, tables, lists) as chunk boundaries - tends to outperform pure token-window splitting on documents with strong structure. The honest answer on chunk size is: tune it on your golden set, do not guess.
Stage 4: Embeddings
The embedding stage decides what "similar" means in your retrieval space. Three families to understand:
- Dense bi-encoders - OpenAI
text-embedding-3-large, Cohere Embed 4, open-source e5/BGE - encode to a single vector, semantic similarity via cosine or dot product. The default for most workloads. - Sparse / learned-sparse - SPLADE and BM25-as-learned-sparse - keep keyword precision while gaining semantic flexibility. Good complement to dense, not a replacement.
- Multi-vector / late-interaction - ColBERT-family - store per-token embeddings, score with MaxSim. Higher recall on hard queries, larger index, more expensive to serve.
Two practical levers:
- Matryoshka representations allow truncating embeddings (e.g., 1536 to 256 dims) with controlled recall loss. Use the truncated dim for fast first-pass retrieval, full dim for reranking - a meaningful storage saving at 10M+ documents.
- Domain fine-tuning of the embedder is worth it when off-the-shelf models score poorly on your golden set. Synthetic query generation from your corpus is a reliable starting point; budget the training and serving cost up front.
The MTEB leaderboard is a starting point, not an answer. Always evaluate on your data.
Stage 5: Indexing on OpenSearch
This is where the pipeline meets the storage substrate. OpenSearch is our default because one cluster handles BM25 lexical search, k-NN vector search, ACL filtering, and aggregations - eliminating the coordination overhead of running a separate vector store.
The core configuration knobs:
- k-NN with HNSW - tune
ef_construction,M, andef_searchfor the recall/latency point that matches your SLA. HigherMraises recall and memory; higheref_searchraises recall and query latency. - Quantisation for cost. OpenSearch 3.6 ships Better Binary Quantization (BBQ) at 32x compression with rescoring oversample. Earlier scalar-quantization options remain available for less aggressive compression. The standard pattern is quantised retrieval for the candidate set, full-precision rescoring on the top-K.
- ACL enforcement. Encode access groups as keyword fields and pre-filter at query time. Pre-filtering is correct (no leak risk) but slower than post-filtering on some queries; OpenSearch's segment-level filter implementation makes pre-filtering acceptable for most workloads. Never post-filter ACLs.
Reindexing strategy is non-negotiable: alias-based blue-green swaps for zero-downtime reindexing, and aliases as the routing layer for A/B testing chunking or embedding changes against live traffic.
Stage 6: Hybrid Retrieval
Pure dense vector retrieval consistently misses what BM25 catches: exact entity names, error codes, identifiers, acronyms - the literal tokens users type. Hybrid is the production default.
OpenSearch supports two fusion modes through search pipelines:
- The normalization processor (introduced in 2.10) normalises and combines BM25 and vector scores using min-max or L2 normalisation followed by weighted arithmetic or geometric mean.
- The score ranker processor (introduced in 2.19) supports Reciprocal Rank Fusion (RRF) - rank-based, parameter-free, robust as a default and resistant to score-distribution drift.
Reach for RRF when you do not want to maintain calibration; reach for normalised score fusion when you need weight-tunable control per query type.
Three retrieval-side techniques worth wiring in:
- Query rewriting with an LLM to decompose multi-part questions and expand acronyms. Cheap, high leverage.
- HyDE (Hypothetical Document Embeddings) - generate a pseudo-answer, embed and retrieve with it. Helps on ambiguous or under-specified queries.
- Metadata filters combined with vector similarity - hard filters on date, document type, department, plus the ACL filter. Apply filters before scoring where possible.
Stage 7: Reranking
Hybrid retrieval gets the right document into the top-50. Reranking moves it into the top-5, which is what the LLM actually reads. The lift is consistent: most production teams measure 5-15 NDCG@10 points, sometimes more on lexically hard datasets.
Cross-encoders score query and candidate jointly with full attention - far more accurate than the bi-encoder similarity that drove first-stage retrieval, but too expensive to apply to all candidates. The standard pattern: retrieve top-50 to top-100, rerank, pass top-3 to top-5 to the generator.
Production-ready options as of 2026:
- Cohere Rerank 3.5 (
rerank-v3.5API name; also available via Amazon Bedrock) - hosted, multilingual, long-document support. - AWS Bedrock Rerank - Cohere and Amazon Rerank models behind a unified API.
- BGE Reranker v2 (
bge-reranker-v2-m3,bge-reranker-v2-gemma) - open weights, self-hostable, strong on BEIR/MTEB.
For a deeper treatment of when reranking pays off and how to evaluate it, see our reranking guide. Latency adds 100-300 ms in typical configurations; budget for it.
Stage 8: Generation
Generation is where the LLM finally sees the retrieved context. Three patterns determine answer quality more than the choice of model:
Context packing. Order matters - put the most relevant chunks first to mitigate the "lost in the middle" effect documented in long-context LLMs. Compress where you can: extract key sentences, summarise long passages. Leave token budget for the system prompt and the output.
Citation enforcement. Prompt the model to emit inline citations ([1], [2]) keyed to the retrieved chunk IDs, then post-process to verify cited spans exist in the retrieved context. For programmatic consumers, return structured JSON with an answer and citations array - it makes downstream verification trivial.
Guardrails. Input guardrails for topic gating and prompt injection detection; output guardrails for hallucination, PII redaction, and brand-safety. Treat hallucination detection as a separate evaluator on top of generation, not as something the generator polices itself.
Stage 9: Evaluation and Operations
Without evaluation gates, every change to chunking, embedding, retrieval, or prompts is a coin flip. Three layers of evaluation:
- Offline regression on a curated golden set (50-500 query-context-answer triples). Metrics: context recall, context precision, answer faithfulness, answer relevancy - the RAGAS framework is the most widely adopted framing. Run on every PR.
- Online evaluation by sampling production traffic and scoring with an LLM-as-judge. Watch for retrieval drift (recall degrading week over week) and embedding distribution shift. Pairs well with a reasoned scepticism toward LLM judges - calibrate the judge against human-labelled samples.
- CI gates. Block deployments that regress retrieval recall or generation faithfulness beyond a threshold. New failure modes from production should be promoted into the regression set.
Observability requires end-to-end traces: query, retrieval candidates, fused scores, reranked candidates, generation prompt, response, latency per stage, token counts. LangSmith, Langfuse, and Arize Phoenix all do this competently. Alert on latency spikes, cost anomalies, and low-confidence generations.
Orchestration: Decision Matrix
The orchestration layer wires the stages together. Choosing wrong adds friction; choosing well buys you streaming, retries, branching, and human-in-the-loop with minimal new code.
| Framework | Strength | Pick when |
|---|---|---|
| LangGraph | Stateful graphs, cycles, human-in-the-loop, streaming | Agentic RAG with conditional branching, multi-step reasoning |
| LlamaIndex Workflows | Tight integration with LlamaIndex connectors and indexes | Already using LlamaIndex for ingestion or indexing |
| Haystack 2.x Pipelines | Strongly-typed components, YAML serialisation, built-in evaluation | Declarative pipelines and a shared component library |
| Plain Python | Zero overhead, full control | Simple linear pipelines, strong engineering discipline |
The graduation point from plain Python to a framework is when you need branching, retries, streaming, or stateful conversations. Until then, plain Python is faster to debug.
Cost Modelling
A representative per-query breakdown for a hosted-API stack:
| Component | Per-query cost (illustrative) |
|---|---|
| Query embedding | ~$0.0001 |
| OpenSearch retrieval (infra-amortised) | $0.0005 - $0.002 |
| Rerank (top-50) | $0.001 - $0.003 |
| Generation (3-5K context, GPT-4o-class) | $0.01 - $0.05 |
| Total | $0.012 - $0.055 |
Numbers will move with your concurrency, model choice, and whether reranking and generation are cached. The biggest levers, in order of typical impact: prompt and KV caching at the LLM provider, batch embedding at ingestion, semantic caching for repeated queries (embed query, nearest-neighbour lookup in a cache index, serve cached answer above a similarity threshold), and reranker model choice.
Production Readiness Checklist
Before traffic switches over, verify:
- Security and access control. ACLs verified end-to-end - ingest, index, query, response. Prompt-injection mitigations in place. Output guardrails for PII.
- Reliability. Blue-green reindexing with rollback. Circuit breakers on LLM and reranker calls. Graceful degradation - serve without reranking if the reranker is down.
- Quality. Golden set with at least 50 representative queries. CI eval gate that blocks on regression. LLM-judge sampling on at least 1% of production traffic.
- Observability. Trace every request end-to-end. Dashboard with p50 and p95 latency, sampled retrieval recall, cost per query, and error rate. Alert thresholds set on each.
The pipeline is not the architecture - the pipeline is the architecture and the operations. Stages exist so that when something breaks, you can point at one place, replace one component, and ship the fix without retesting the world. That is the actual return on doing this right.
Key takeaways
- A production RAG system is a nine-stage pipeline: ingestion, parsing, chunking, embedding, indexing, retrieval, reranking, generation, and evaluation.
- Capture ACLs at ingestion. Retrofitting them later is architecturally expensive and leak-prone.
- Hybrid retrieval (BM25 + dense) with RRF fusion outperforms pure-vector retrieval on real-world queries; OpenSearch handles both natively through search pipelines.
- Reranking lifts NDCG@10 by 5-15 points with 100-300 ms of added latency - the highest-leverage upgrade for most pipelines.
- Eval gates in CI are not optional. Without them, retrieval quality silently drifts after every change.
If you are designing or hardening a production RAG system, our consulting team has shipped these pipelines on OpenSearch, Elasticsearch, and Bedrock across regulated and high-throughput workloads.

